
Nội dung
Robots.txt là gì?
Robots.txt là một tệp văn bản đơn giản có đuôi mở rộng .txt nằm trong thư mục gốc của trang web. Tệp này chứa các chỉ thị cho các trình thu thập thông tin của các công cụ tìm kiếm, chẳng hạn như Googlebot, Bingbot,… Các chỉ thị này cho biết các trình thu thập thông tin có thể truy cập và thu thập dữ liệu từ những phần nào của trang web.
File robots.txt có chức năng gì?
Chức năng chính của robots.txt là giúp quản lý lưu lượng thu thập dữ liệu của các công cụ tìm kiếm. File này có thể được sử dụng để làm các công việc như
- Ngăn các trình thu thập thông tin truy cập vào các phần của trang web mà bạn không muốn chúng thu thập dữ liệu.
- Yêu cầu các trình thu thập thông tin thu thập dữ liệu từ các phần của trang web với tần suất thấp hơn.
- Sắp xếp thứ tự thu thập dữ liệu của các trình thu thập thông tin.
Cấu trúc của file robots.txt
File robots.txt có cấu trúc khá là đơn giản, bao gồm các dòng chỉ thị. Mỗi dòng chỉ thị bắt đầu bằng một từ khóa và sau đó là một hoặc nhiều tham số.
Các từ khóa thường gặp trong robots.txt bao gồm:
- User-agent: Chỉ định loại trình thu thập thông tin mà chỉ thị này áp dụng.
- Disallow: Chỉ định các URL mà trình thu thập thông tin không được phép truy cập.
- Allow: Chỉ định các URL mà trình thu thập thông tin được phép truy cập.
- Sitemap: Chỉ định URL của sitemap của trang web.
Trình thu thập dữ liệu của Google hỗ trợ những lệnh nào?
Trước khi tạo bạn cần hiểu các lệnh mà Google hỗ trợ. Vì Google là công cụ chính để chúng ta sử dụng và khai báo website.
Bên dưới là một ví dụ minh hoạ cho một mẫu robots.txt
# Ví dụ 1: Ngăn chặn Googlebot
User-agent: Googlebot
Disallow: /
# Ví dụ 2: Ngăn chặn Googlebot và Adsbot
User-agent: Googlebot
User-agent: Adsbot
Disallow: /
# Ví dụ 3: Chặn tất cả các trình thu thập thông tin trừ Adsbot
User-agent: *
Disallow: /
User-Agent
Bắt buộc, ít nhất một lệnh trong mỗi nhóm. Quy tắc này quy định rằng tên của ứng dụng tự động (còn được gọi là trình thu thập dữ liệu của công cụ tìm kiếm) phải tuân theo quy tắc đó. Đây là câu đầu tiên của mỗi nhóm quy tắc. Danh sách các tác nhân người dùng của Google liệt kê tên các tác nhân người dùng của Google. Dấu hoa thị (*) đại diện cho mọi trình thu thập dữ liệu, trừ trình thu thập dữ liệu AdsBot (bạn phải nêu rõ tên cho loại trình thu thập dữ liệu này).
Disallow
Ít nhất một mục disallow hoặc allow trong mỗi quy tắc. Một thư mục hoặc trang (tương đối so với miền gốc) mà bạn không muốn tác nhân người dùng thu thập dữ liệu trên đó. Nếu quy tắc đề cập đến một trang, thì tên trang đó phải được ghi đầy đủ (như tên xuất hiện trong trình duyệt). Quy tắc này phải bắt đầu bằng một ký tự / và nếu quy tắc này đề cập đến một thư mục, thì thư mục đó phải kết thúc bằng một dấu /.
Allow
Ít nhất một mục disallow hoặc allow trong mỗi quy tắc. Một thư mục hoặc trang (tương đối so với miền gốc) mà tác nhân người dùng được phép thu thập dữ liệu trên đó. Quy tắc này được sử dụng để ghi đè lên quy tắc disallow để cho phép thu thập dữ liệu trên một thư mục con hoặc một trang trong một thư mục không được phép. Đối với một trang đơn lẻ, hãy chỉ định tên trang đầy đủ như tên xuất hiện trong trình duyệt. Quy tắc này phải bắt đầu bằng một ký tự / và nếu quy tắc này đề cập đến một thư mục, thì thư mục đó phải kết thúc bằng một dấu /.
Sitemap
Không bắt buộc, có hoặc không có trong mỗi tệp. Vị trí của sơ đồ trang web cho trang web này. URL sơ đồ trang web phải là một URL đủ điều kiện; Google không giả định hoặc kiểm tra các phiên bản thay thế (http/https/www/không có www). Sơ đồ trang web là một cách hay để chỉ định nội dung mà Google nên thu thập dữ liệu, chứ không phải nội dung mà Google được phép hoặc không được phép thu thập dữ liệu.
Hướng dẫn tạo file robots.txt cho website
Hiện tại các công cụ SEO như RankMath, YoastSEO đã hỗ trợ bạn tạo file, nhưng bạn sẽ không thể tìm thấy file này trong thư mục mã nguồn của bạn, và bạn sẽ không thể chủ động sửa file. Vì vậy tốt hơn hết hạn hãy tạo thủ công và viết các quy tắc cho riêng bạn.
Cách thức tạo rất đơn giản, bên trong host hoặc VPS. Bạn di chuyển vào vị trí chứa mã nguồn vào tạo mới một file và đặt tên là robots.txt
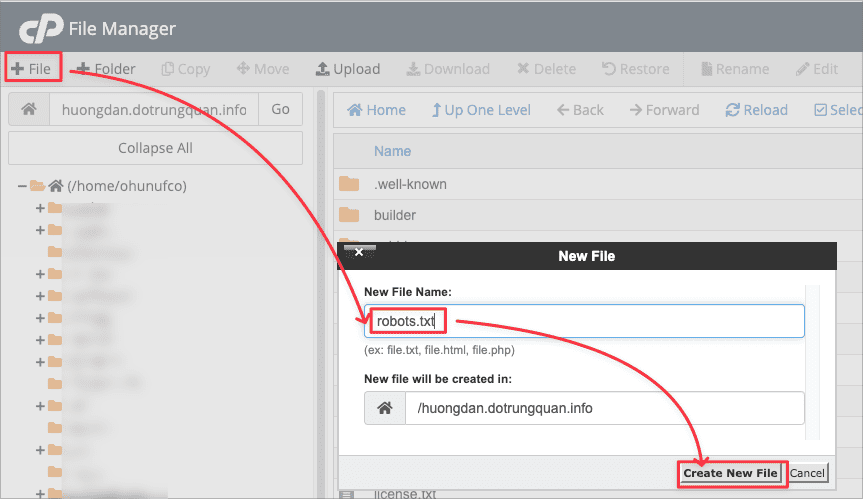
Sau đó bạn nhập vào nội dung mẫu cơ bản sau trong file robots.txt vừa tạo.
Lưu ý: Đây là một mẫu cơ bản cho website WordPress. Không có mẫu chuẩn áp dụng toàn bộ hệ thống website vì mỗi web đều khác nhau. Vì vậy bạn hãy thiết lập một cấu hình theo nhu cầu sử dụng và phù hợp với web của bạn.
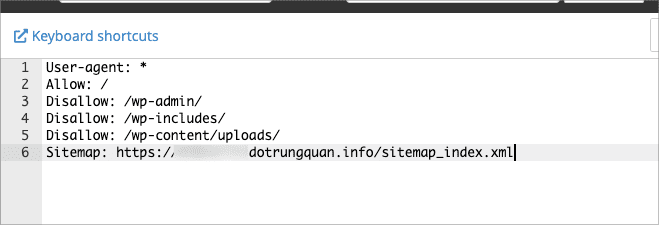
Đây là mẫu riêng của tôi sử dụng cho website cá nhân của tôi. Bạn có thể dựa vào cấu hình này và viết lại quy tắc riêng cho bạn.
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /search?q=*
Disallow: *?replytocom
Disallow: */attachment/*
Disallow: /images/
Disallow: */feed/
Allow: /*.js$
Allow: /*.css$
Sitemap: Nhập vào đường dẫn link sitemap
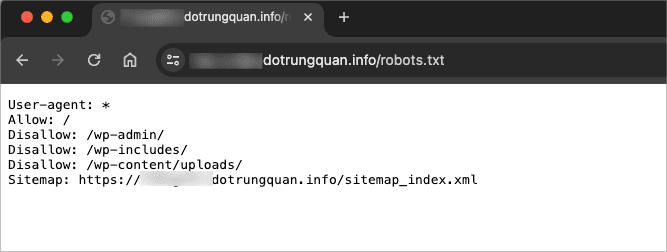
Và bây giờ bạn hãy truy cập đường dẫn https://my-domain/robots.txt. Nếu kết quả hiển thị như bạn nhập thì đã thành công.
Lưu ý khi sử dụng robots.txt
- Robots.txt không phải là một phương pháp để ẩn trang web khỏi các công cụ tìm kiếm. Các công cụ tìm kiếm có thể bỏ qua các chỉ thị robots.txt nếu chúng cho rằng các chỉ thị này không hợp lệ hoặc có hại.
- Robots.txt chỉ là một hướng dẫn cho các trình thu thập thông tin. Các trình thu thập thông tin có thể bỏ qua các chỉ thị robots.txt nếu chúng cho rằng các chỉ thị này không hợp lý hoặc không có lợi cho người dùng.
Tóm lại, robots.txt là một tệp quan trọng giúp bạn quản lý lưu lượng thu thập dữ liệu của các công cụ tìm kiếm. Bằng cách sử dụng robots.txt một cách hợp lý, bạn có thể cải thiện hiệu quả thu thập dữ liệu của các công cụ tìm kiếm và tối ưu hóa trang web của mình cho SEO.
Chúc bạn thực hiện thành công
Nếu các bạn cần hỗ trợ các bạn có thể liên hệ bộ phận hỗ trợ theo các cách bên dưới:
- Hotline 247: 028 888 24768
- Ticket/Email: Bạn dùng email đăng ký dịch vụ gửi trực tiếp về: support@azdigi.com.
