
Ở phần 8 của serie, mình đã tách frontend và backend thành các chart riêng, rồi ghép chúng lại bằng Helm theo kiểu đủ sạch để còn scale tiếp. Sang phần này, câu chuyện chuyển hẳn sang production: Nginx đứng ở đâu, ingress nên route thế nào, rollout ra sao để người dùng không thấy gián đoạn, và vì sao chỉ deploy được thôi thì vẫn chưa đủ.
Case lab vẫn là một full-stack app quen thuộc: frontend NodeJS build ra static assets, backend Express phục vụ API, mọi thứ chạy trên Kubernetes. Khác biệt nằm ở chỗ mình không còn nhìn stack này như một bản demo. Từ đây trở đi, các quyết định về reverse proxy, TLS, health check, autoscaling và security context bắt đầu ảnh hưởng trực tiếp tới độ ổn định của hệ thống.
ℹ️ Bài này giả định bạn đã có chart cho frontend và backend, đã hiểu Deployment, Service, values và cách Helm render template. Nếu chưa, nên xem lại các phần trước trong serie trước khi đi tiếp.
Vì sao cần reverse proxy trong production
Ở môi trường dev, bạn có thể mở thẳng service NodeJS ra ngoài, gõ IP kèm port rồi test. Production mà làm vậy thì khá mệt. Frontend, backend, TLS certificate, cache header, gzip, rate limit, log chuẩn hóa, mấy thứ này đều rơi vào tay ứng dụng. NodeJS làm được một phần, nhưng đó không phải điểm mạnh của nó.
Reverse proxy xuất hiện để gom các việc ở lớp biên lại một chỗ. Nó nhận request từ internet, quyết định request nào đi vào frontend, request nào chuyển tới API, chỗ nào cần cache, chỗ nào cần giữ nguyên, chỗ nào phải ép HTTPS. Khi có thêm nhiều replica, reverse proxy còn giúp phân phối tải đều hơn và che bớt chi tiết bên trong cluster.
- Tách trách nhiệm: app tập trung xử lý nghiệp vụ, proxy lo routing và policy ở lớp truy cập.
- Giảm độ lộ diện: người dùng chỉ thấy domain public, không thấy topology thật của service phía sau.
- Dễ tối ưu hơn: gzip, cache asset, keepalive, header bảo mật đều cấu hình tập trung.
- Dễ thay đổi hạ tầng: scale pod, đổi service name, thêm replica thường không làm thay đổi URL public.
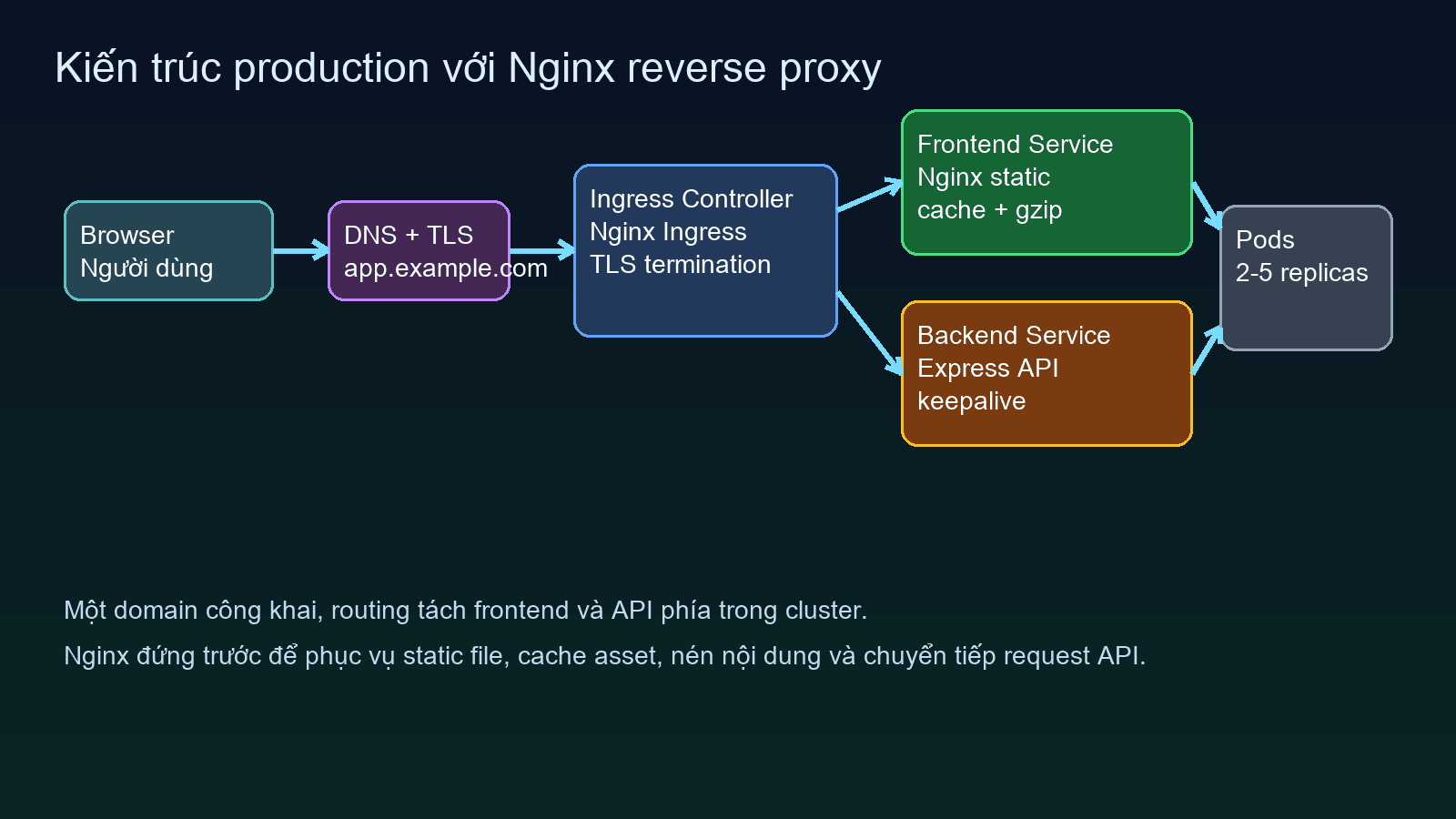
Cái hay của reverse proxy là nó cho bạn một lớp đệm hợp lý giữa internet và workload thật. Đặc biệt với full-stack app, frontend thường cần phục vụ asset tĩnh rất nhanh, còn backend lại cần giữ kết nối ổn định với upstream hoặc database. Gộp hai kiểu traffic này vào cùng một cách xử lý sẽ khó tối ưu. Tách bằng Nginx hoặc ingress controller thì sạch hơn nhiều.
Nginx cho full-stack: static, API proxy, cache, compression
Với frontend kiểu React SPA hoặc Next.js export static, Nginx rất hợp để đứng trước. Nó phục vụ asset tĩnh tốt, hiểu cache header, nén nội dung gọn, và xử lý SPA fallback ngon hơn việc dùng một process Node chỉ để serve file build.
Mẫu dưới đây là một cấu hình khá thực dụng cho frontend + API proxy. Chỗ này không cố nhồi mọi directive nâng cao của Nginx, chỉ giữ những thứ hay dùng nhất trong production.
server {
listen 8080;
server_name _;
root /usr/share/nginx/html;
index index.html;
gzip on;
gzip_types text/plain text/css application/json application/javascript application/xml+rss image/svg+xml;
gzip_min_length 1024;
location /assets/ {
expires 30d;
add_header Cache-Control "public, max-age=2592000, immutable";
try_files $uri =404;
}
location /api/ {
proxy_pass http://backend-svc:3000/;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Connection "";
proxy_read_timeout 60s;
proxy_connect_timeout 5s;
}
location / {
add_header Cache-Control "no-store";
try_files $uri $uri/ /index.html;
}
}Mấy điểm đáng để ý trong config này:
/assets/được cache dài ngày vì file build thường có hash trong tên. Đổi bản build là đổi tên file, nên cache mạnh tay vẫn an toàn./api/dùngproxy_passđể chuyển tiếp sang backend service. HeaderX-Forwarded-*giúp app biết được client IP và scheme thật./dùngtry_filesđể hỗ trợ SPA routing. Nếu người dùng refresh ở/dashboard, Nginx vẫn trả vềindex.html.- gzip giúp giảm dung lượng cho JS, CSS, JSON. Với tài nguyên text thì lợi khá rõ.
💡 Nếu frontend của bạn là Next.js SSR, Nginx vẫn hữu ích nhưng vai trò hơi khác. Nó sẽ đứng trước Next server để xử lý TLS, cache ở mép ngoài, static asset, header và giới hạn truy cập, thay vì thay hẳn runtime ứng dụng.
runtime config và API base URL
Một lỗi rất hay gặp là hardcode API URL ngay từ lúc build frontend. Lên production rồi đổi domain, đổi ingress host hoặc tách API sang subdomain là lại phải build lại image. Gọn hơn là inject config ở runtime.
window.__APP_CONFIG__ = {
API_BASE_URL: "/api"
};Config kiểu này có thể mount bằng ConfigMap và phục vụ cùng frontend. Nhờ vậy một image có thể dùng cho nhiều môi trường, còn URL API được quyết định ở lúc deploy. Helm rất hợp với pattern này vì mỗi môi trường chỉ cần đổi values, không phải chạm lại pipeline build.
caching và compression nên đặt ở đâu
Asset tĩnh nên cache ở Nginx hoặc CDN, còn API response thì cẩn thận hơn. Danh sách sản phẩm ít đổi có thể cache ngắn vài chục giây hoặc vài phút. Endpoint chứa trạng thái phiên đăng nhập, token hoặc dữ liệu theo người dùng thì đừng cache bừa. Chỗ này làm ẩu là dễ sinh bug kiểu người dùng A thấy dữ liệu của người dùng B.
Compression cũng vậy. Bật gzip cho JSON, CSS, JS là bình thường. Ảnh JPEG, PNG, WebP đã nén sẵn rồi thì nén lại không có nhiều ý nghĩa. Hiểu nhanh thì proxy nên tối ưu mạnh cho nội dung text, còn file media để CDN hoặc object storage lo tiếp.
Production ingress: controller, TLS, domain routing, load balancing
Trong Kubernetes, ingress là lớp khai báo luật truy cập HTTP và HTTPS. Còn thứ thực thi mấy luật đó là ingress controller, ví dụ NGINX Ingress Controller hoặc Traefik. Nói ngắn thì ingress resource là config, controller mới là engine.
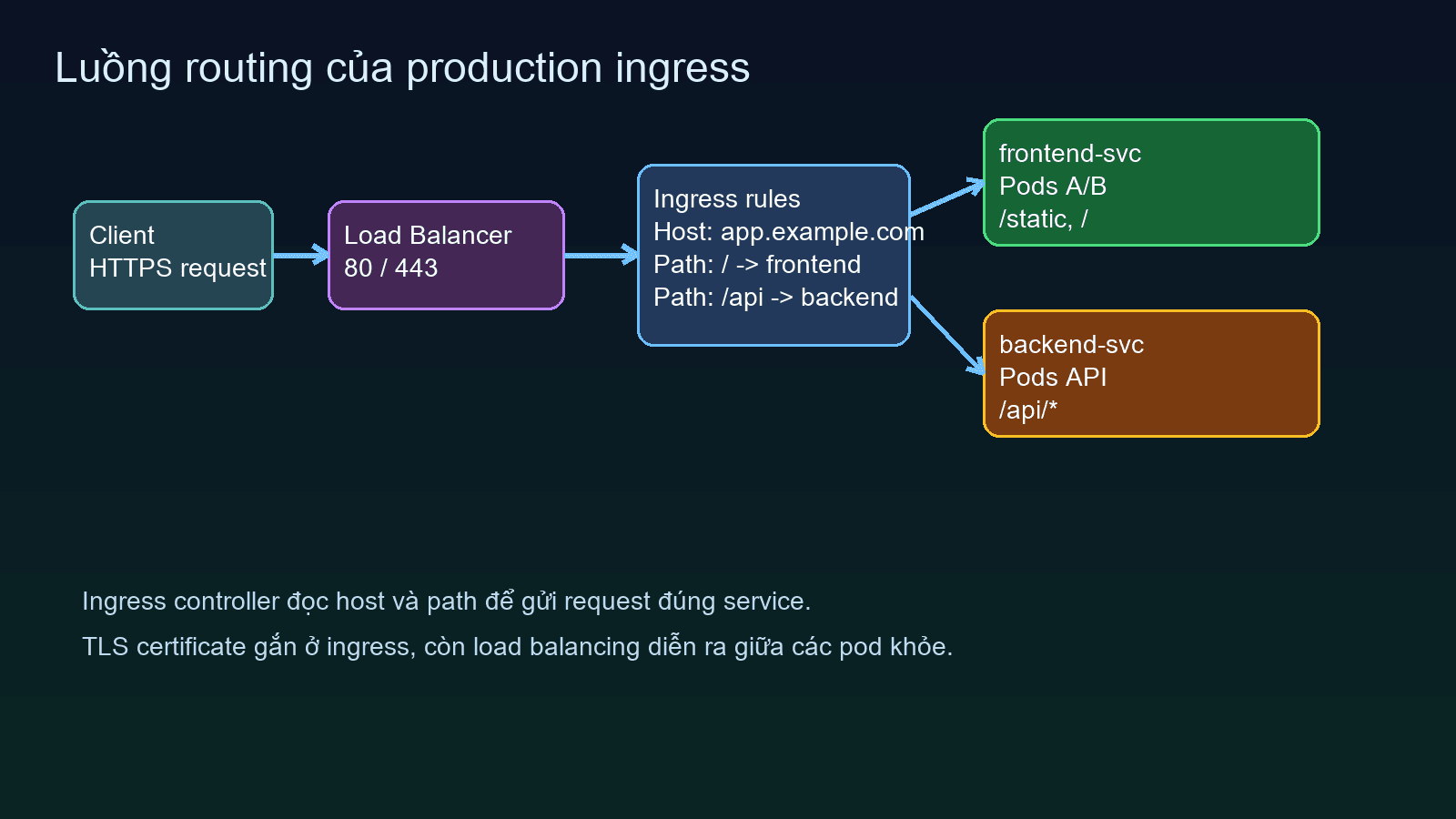
Với full-stack app, bạn thường gặp hai kiểu route:
- Một domain, tách theo path:
app.example.com/vào frontend vàapp.example.com/apivào backend. - Tách theo host:
app.example.comcho frontend,api.example.comcho backend.
Path-based routing tiện khi muốn trình duyệt chỉ thấy một origin, CORS đỡ rối. Host-based routing lại rõ ràng hơn cho API, dễ áp chính sách riêng như rate limit, WAF hoặc cache policy. Không có lựa chọn nào thắng tuyệt đối, nhưng nếu backend sẽ lớn dần thành một bề mặt riêng thì tách host thường khỏe hơn về sau.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: fullstack-ingress
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/proxy-body-size: 10m
spec:
ingressClassName: nginx
tls:
- hosts:
- app.example.com
secretName: app-example-com-tls
rules:
- host: app.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: frontend-svc
port:
number: 80
- path: /api
pathType: Prefix
backend:
service:
name: backend-svc
port:
number: 3000Đây là mẫu path-based khá phổ biến. Phần TLS được gắn ngay trong ingress, thường đi cùng cert-manager để tự xin và gia hạn chứng chỉ Let’s Encrypt. Chỗ này giúp vòng đời certificate nằm trong Kubernetes, đỡ phụ thuộc thao tác thủ công.
TLS, SSL và HTTPS enforcement
Ở production, HTTP gần như chỉ nên tồn tại để redirect sang HTTPS. Ngoài chuyện bảo mật, rất nhiều tính năng hiện đại của trình duyệt cũng giả định site chạy trên HTTPS. Nếu để song song cả HTTP lẫn HTTPS quá thoải mái, bạn dễ gặp tình trạng cookie không nhất quán, mixed content hoặc callback URL đi sai scheme.
Thực tế triển khai thường theo chuỗi này: Load Balancer mở 80 và 443, ingress controller nhận lưu lượng, cert-manager gắn cert, annotation hoặc config ép redirect sang HTTPS. Sau đó ứng dụng tin vào header X-Forwarded-Proto để biết request gốc là HTTPS.
load balancing ở đâu diễn ra
Nhiều bạn mới làm Kubernetes hay nghĩ ingress đã cân tải xong thì service không còn vai trò gì. Thực ra nó là nhiều lớp. Cloud Load Balancer cân tải vào các node hoặc ingress pod, ingress controller cân tiếp vào service, rồi service lại phân phối traffic giữa các pod backend khỏe mạnh. Càng về phía trong, quyết định này càng dựa vào endpoint đang sẵn sàng.
Nhờ cách chia lớp này, bạn có thể scale ingress pod theo lưu lượng vào, còn backend pod scale theo request xử lý thật. Hai vấn đề khác nhau, nên việc đo và scale cũng nên khác nhau.
Zero-downtime deployment: rolling updates, readiness probes, PreStop hooks
Đa số downtime khi deploy không đến từ Kubernetes hỏng, mà đến từ việc pod được tính là sẵn sàng quá sớm hoặc bị tắt quá nhanh. Nếu app chưa boot xong mà readiness đã pass, ingress sẽ gửi traffic vào pod mới và trả lỗi. Nếu pod cũ bị kill ngay lúc đang giữ kết nối, request dở dang sẽ rơi mất.
Muốn rollout êm, bạn cần ít nhất ba mảnh ghép phối hợp với nhau:
- RollingUpdate strategy để không thay toàn bộ pod cùng lúc.
- Readiness probe để chỉ nhận traffic khi app thật sự đã phục vụ được.
- PreStop hook + termination grace period để pod cũ có thời gian drain request trước khi thoát.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
maxSurge: 1
containers:
- name: api
image: ghcr.io/example/fullstack-api:1.0.0
ports:
- containerPort: 3000
readinessProbe:
httpGet:
path: /healthz/ready
port: 3000
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10"]
terminationGracePeriodSeconds: 30maxUnavailable: 0 là chi tiết rất đáng tiền. Nó buộc Kubernetes luôn giữ đủ số pod cũ trong lúc đưa pod mới lên. Với backend xử lý request thật, setting này giúp tránh khoảng trống năng lực phục vụ lúc rollout.
Còn readiness probe nên kiểm tra thứ phản ánh đúng trạng thái phục vụ, không chỉ là process còn sống. Nếu endpoint chỉ trả 200 vì app boot xong nhưng kết nối database vẫn chưa ready, probe đó gần như vô dụng. Nôm na là probe phải trả lời câu hỏi: “Pod này nhận traffic ngay bây giờ có an toàn chưa?”
Với NodeJS, PreStop thường được dùng để báo ứng dụng ngừng nhận kết nối mới, đợi request hiện tại xử lý xong, rồi mới thoát. Chỉ sleep 10 thôi chưa phải chuẩn đẹp, nhưng nó vẫn tốt hơn việc kill gấp. Nếu app của bạn có graceful shutdown thật, hãy bắt SIGTERM và đóng server đúng cách.
const server = app.listen(3000);
process.on('SIGTERM', () => {
server.close(() => {
process.exit(0);
});
});⚠️ Nếu bạn đang chạy WebSocket, SSE hoặc request dài, phần graceful shutdown còn quan trọng hơn nữa. PreStop ngắn quá là client rớt kết nối thấy rõ.
Tối ưu hiệu năng: resource limits, HPA, connection pooling
Tối ưu production hiếm khi đến từ một nút thần kỳ. Nó là nhiều lớp nhỏ cộng lại. Nếu không đặt requests và limits, scheduler khó quyết định pod nên nằm ở đâu. Nếu không có HPA, khi traffic tăng bạn chỉ còn cách ngồi nhìn pod full CPU. Nếu không kiểm soát kết nối ra database hoặc upstream, scale càng nhiều lại càng dễ tự bóp cổ mình.

requests và limits
Ít nhất bạn nên đặt resources.requests cho từng workload. Nó cho scheduler biết pod cần bao nhiêu CPU và RAM để đặt lịch. limits thì giúp ngăn một pod ăn sạch tài nguyên node. Không phải lúc nào cũng cần limits thật chặt, nhưng để trống hoàn toàn ở production là hơi liều.
resources:
requests:
cpu: 200m
memory: 256Mi
limits:
cpu: 500m
memory: 512MiFrontend Nginx thường nhẹ hơn backend API. Đừng lấy một profile tài nguyên rồi nhét cho cả hai bên. Làm vậy nhìn có vẻ đồng bộ nhưng thực ra chỉ làm cho autoscaling và capacity planning kém chính xác hơn.
HPA và metric phù hợp
Horizontal Pod Autoscaler thường bắt đầu bằng CPU hoặc memory, nhưng đó chỉ là mốc khởi động. Với API, request per second, latency hoặc queue length nhiều lúc phản ánh đúng tải hơn. Dù vậy nếu hạ tầng của bạn mới ở mức cơ bản, scale theo CPU vẫn đủ thực dụng để đem lại khác biệt.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: backend-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: backend
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70Đừng quên kiểm tra lại readiness và startup time trước khi bật HPA. Nếu scale lên rất nhanh nhưng pod mới mất 40 giây mới ready, hệ thống vẫn có thể hụt tải trong các đợt traffic spike.
connection pooling và keepalive
Scale pod không có nghĩa là muốn mở bao nhiêu kết nối xuống database cũng được. Đây là bẫy khá quen thuộc với NodeJS. Ví dụ mỗi pod mở 20 kết nối PostgreSQL, HPA scale lên 10 pod là database phải chịu 200 kết nối chỉ từ một service. Chưa tính worker, migration job hay các app khác.
Vì vậy phải nhìn kết nối theo cấp hệ thống. Dùng pool vừa phải ở app, giữ keepalive hợp lý ở Nginx hoặc ingress, và nếu cần thì dùng thêm lớp pool chuyên dụng như PgBouncer. Chỗ này tối ưu quá tay cũng dở, nhưng không kiểm soát thì dễ đụng trần database trước khi CPU trên pod kịp tăng.
Bảo mật: network policies, security contexts, HTTPS enforcement
Production không chỉ là chạy ổn định. Nó còn phải giới hạn được phạm vi hỏng và bề mặt tấn công. Mặc định nhiều cluster cho phép pod nói chuyện khá thoải mái với nhau. Nếu không chặn từ sớm, một workload bị compromise có thể quét ngang sang service khác dễ hơn bạn nghĩ.

network policy
NetworkPolicy giúp bạn mô tả pod nào được phép nói chuyện với pod nào. Với full-stack app, frontend không nhất thiết phải gọi mọi service trong namespace. Nó thường chỉ cần ra backend hoặc đi tới object storage, CDN, API bên ngoài nào đó đã biết trước. Càng thu hẹp đường đi, hậu quả khi có sự cố càng nhỏ.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: backend-allow-from-ingress
spec:
podSelector:
matchLabels:
app.kubernetes.io/name: backend
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: ingress-nginx
ports:
- protocol: TCP
port: 3000Đây là ví dụ tối giản cho phép backend chỉ nhận lưu lượng từ ingress namespace. Trong hệ thống thật, bạn có thể mở thêm rule cho monitoring hoặc internal job nếu thật sự cần. Quan trọng là phải bắt đầu từ tư duy mặc định chặt, rồi mở đúng chỗ, thay vì mở toang rồi hy vọng không ai đi lạc.
security context
Nếu image của bạn vẫn chạy bằng root, ghi thoải mái lên filesystem và mount đủ thứ không cần thiết, thì production đó hơi mong manh. Security context giúp ép container chạy bằng user không đặc quyền, khóa bớt khả năng ghi, và hạ quyền Linux capability xuống mức cần thiết.
securityContext:
runAsNonRoot: true
runAsUser: 10001
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALLTất nhiên không phải app nào cũng bật được readOnlyRootFilesystem ngay. Có app vẫn cần thư mục tạm hoặc cache. Lúc đó bạn mount riêng một volume nhỏ đúng chỗ cần ghi, thay vì mở cả root filesystem cho tiện. Bảo mật production thường là kiểu chỉnh nhiều con ốc nhỏ như vậy.
HTTPS enforcement và secret hygiene
HTTPS nên được ép ở ingress để tránh request đi vào app bằng HTTP ngoài ý muốn. Song song với đó, secret như database URL, JWT secret, API token không nên nhét vào image hoặc commit nguyên trong repo values. Helm có thể render secret, nhưng phần quản trị vòng đời secret vẫn nên tách rõ, ví dụ dùng External Secrets hoặc ít nhất là pipeline inject ở lúc deploy.
🚨 Đừng để endpoint health check hoặc debug route lộ quá nhiều thông tin. Trả về 200 là đủ. Những thứ như version chi tiết, env name, host nội bộ hoặc danh sách dependency không nên phơi ra ngoài internet.
kết lại
Từ phần này trở đi, Helm không còn chỉ là công cụ đóng gói manifest. Nó trở thành cách bạn chuẩn hóa vận hành cho cả một stack full-stack. Nginx lo lớp biên, ingress chịu trách nhiệm route và TLS, Kubernetes giữ rollout an toàn, còn HPA và policy giúp hệ thống chịu tải ổn định hơn mà vẫn giữ được kỷ luật bảo mật.
Nếu nhìn lại toàn bộ mạch bài, bạn sẽ thấy production stack khỏe không đến từ một mẹo đơn lẻ. Nó đến từ nhiều quyết định nhỏ nhưng đúng chỗ: asset nào cache được, probe nào phản ánh readiness thật, connection pool đặt bao nhiêu, pod nào được nói chuyện với ai. Càng làm sớm, về sau càng đỡ trả nợ kỹ thuật.
Sang phần 10 của serie, mình sẽ gom các mảnh này lại theo góc nhìn multi-environment: dev, staging, production nên chia values ra sao, chỗ nào dùng override file, chỗ nào dùng secret ngoài, và làm thế nào để một chart vẫn giữ được sự rõ ràng khi số môi trường bắt đầu tăng lên.
FAQ về production deployment
Có nên để Nginx trong frontend container nếu đã có NGINX Ingress Controller?
Thường là có, nếu frontend của bạn build ra static file. Ingress controller lo lớp truy cập bên ngoài cluster, còn Nginx trong frontend container lo serve file tĩnh, cache header và SPA fallback. Hai vai trò này không trùng hẳn nhau.
Readiness probe và liveness probe khác nhau ở chỗ nào?
Readiness quyết định pod có được nhận traffic hay không. Liveness quyết định Kubernetes có nên restart pod đó không. Với rollout production, readiness thường ảnh hưởng trực tiếp tới việc có downtime hay không, nên phải chăm kỹ hơn.
HPA chỉ scale theo CPU có đủ chưa?
Đủ để bắt đầu, nhất là khi bạn chưa có hệ metric tốt hơn. Nhưng về lâu dài, API thường nên nhìn thêm latency, request rate hoặc queue length. CPU không phải lúc nào cũng phản ánh đúng mức nghẽn của ứng dụng.
Có nên cho backend nhận traffic trực tiếp, bỏ qua ingress?
Chỉ nên làm với service nội bộ hoặc trường hợp rất đặc thù. Với bề mặt public, ingress giúp gom TLS, routing, logging và policy vào một lớp chung. Bỏ lớp này đi thì app phải tự gánh nhiều việc hơn.
NetworkPolicy có bắt buộc không?
Nó không phải tính năng bắt buộc để cluster chạy, nhưng gần như là thứ nên có khi đã lên production nghiêm túc. Nếu chưa bật ngay cho toàn cluster, ít nhất hãy áp cho các namespace hoặc workload nhạy cảm trước.
Có thể bạn cần xem thêm
- NodeJS Full-Stack trong Helm phần 1: Kiến trúc chart cho React/Next.js + Express (Phần 7/11)
- NodeJS Full-Stack trong Helm phần 2: Thêm PostgreSQL + Redis dependencies (Phần 8/11)
- Tự đóng gói ứng dụng Node.js cơ bản thành Helm chart (Phần 6/11)
- Multi-environment deployment với Helm: Dev, Staging, Production (Phần 10/11)
- Deploy ứng dụng từ public repository: Bitnami, Artifact Hub và best practices (Phần 5/11)
- Cài đặt Helm và dựng lab Kubernetes local với kind/OrbStack (Phần 2/11)
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.