
Ở bài 9 của serie Helm, mình đã đi vào chuyện đưa chart lên production: ingress, rollout, tối ưu tài nguyên và các điểm dễ vấp khi chạy thật. Sang phần này, câu chuyện dịch thêm một tầng nữa. Nhiều team không chỉ có một cụm production, mà còn phải giữ song song môi trường dev và staging để kiểm thử, review tính năng và giảm rủi ro trước khi phát hành.
Helm rất hợp với bài toán đó vì cùng một chart có thể tái sử dụng cho nhiều môi trường. Nhưng nếu dùng thiếu kỷ luật, bạn sẽ rơi vào cảnh values chồng chéo, secrets nằm rải rác, staging lệch production, còn pipeline thì deploy kiểu may rủi. Chỗ khó không nằm ở lệnh helm upgrade, mà nằm ở cách tổ chức chart để sau này cả team còn sống khoẻ.
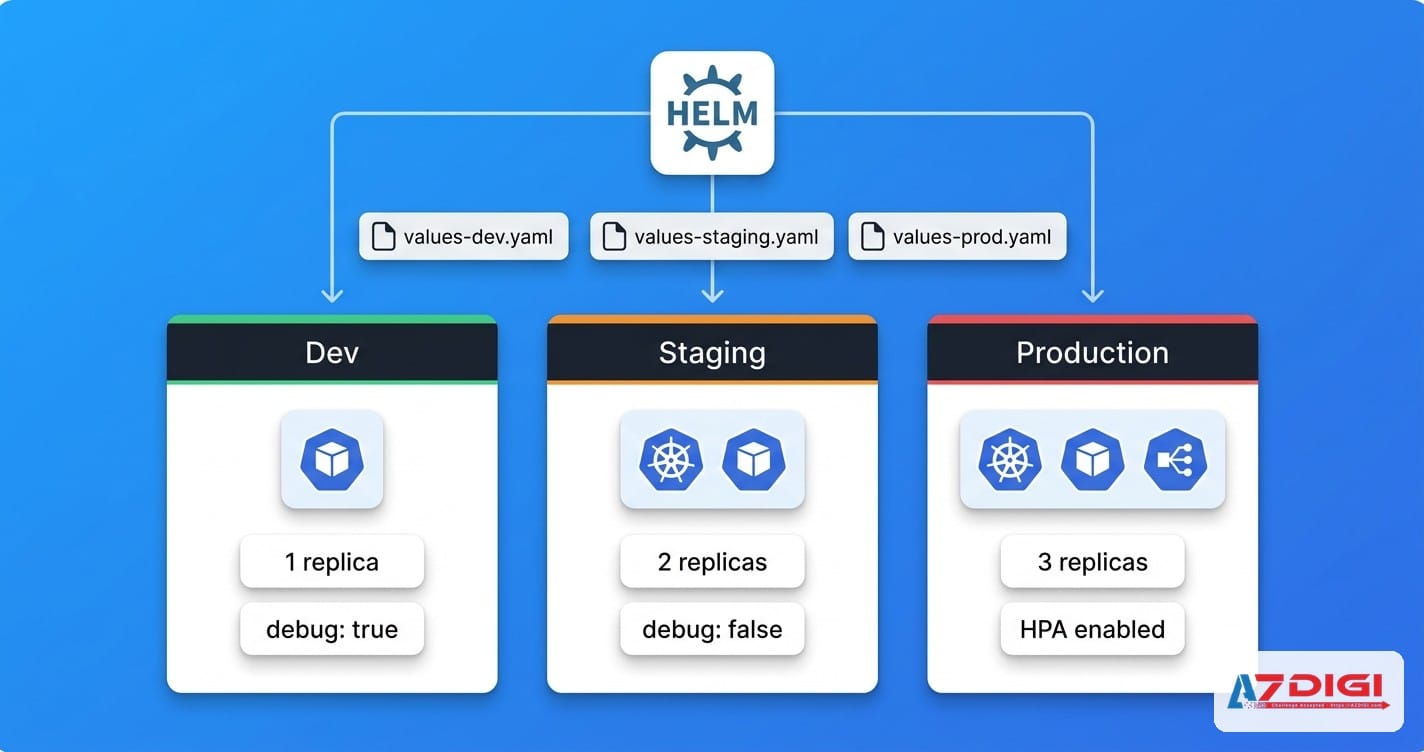
Những thách thức của multi-environment deployment
Khi mới bắt đầu với Helm, nhiều người hay đi theo kiểu đơn giản: một chart, một file values.yaml, cần gì thì sửa thẳng trong đó. Lúc chỉ có môi trường dev thì cách này còn tạm ổn. Nhưng đến lúc có thêm staging và production, mọi thứ bắt đầu rối. Cùng một ứng dụng nhưng mỗi môi trường lại có replica khác nhau, mức tài nguyên khác nhau, endpoint khác nhau, đôi khi cả database và domain cũng khác.
Rủi ro lớn nhất là drift, tức các môi trường trông có vẻ giống nhau nhưng thực tế lại lệch nhau dần theo thời gian. Dev đang dùng image tag mới, staging còn file values cũ, production thì có vài override được thêm bằng tay từ ba tuần trước. Khi bug chỉ xuất hiện ở production, bạn sẽ rất khó tái hiện nếu staging không đủ giống.
- Khác biệt cấu hình: replicas, CPU/RAM, domain, bật tắt feature flag.
- Khác biệt dữ liệu: dev dùng database seed, staging dùng snapshot, production dùng dữ liệu thật.
- Khác biệt quyền hạn: dev thường thoáng hơn, production phải siết chặt RBAC.
- Khác biệt quy trình: dev cho phép deploy liên tục, production cần approval hoặc promote chart đã kiểm thử.
⚠️ Sai lầm hay gặp là cố làm cho dev và production giống hệt về dữ liệu, quyền truy cập và tốc độ thay đổi. Thứ nên giống là kiến trúc triển khai và hành vi của chart. Thứ nên khác là mức độ an toàn và tài nguyên.
Chiến lược values files: giữ gốc ổn định, override đúng chỗ
Cách dễ quản nhất là xem values.yaml như lớp mặc định cho toàn bộ chart. File này chỉ nên chứa những giá trị dùng chung: tên image repository, port mặc định, cấu trúc ingress, probe, toggle của các thành phần phụ. Mỗi môi trường sau đó có một file override riêng như values-dev.yaml, values-staging.yaml và values-prod.yaml.
Mẫu cấu trúc thư mục thường thấy:
myapp-chart/
├── Chart.yaml
├── values.yaml
├── values-dev.yaml
├── values-staging.yaml
├── values-prod.yaml
└── templates/Điểm hay của cách này là bạn đọc rất nhanh. Muốn biết chart mặc định làm gì, mở values.yaml. Muốn biết production khác gì, mở values-prod.yaml. Không cần lục lại lịch sử shell để xem ai đã thêm --set replicaCount=5 trong pipeline hôm nọ.
Ví dụ một values.yaml tương đối sạch:
image:
repository: registry.example.com/myapp
tag: "1.0.0"
pullPolicy: IfNotPresent
replicaCount: 1
service:
type: ClusterIP
port: 80
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 300m
memory: 256Mi
ingress:
enabled: true
className: nginx
host: app.example.local
database:
host: postgres.default.svc.cluster.local
name: myapp
featureFlags:
debugToolbar: falseVới dev, bạn chỉ override những gì thực sự khác:
replicaCount: 1
ingress:
host: dev.myapp.internal
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 200m
memory: 128Mi
database:
host: postgres-dev.default.svc.cluster.local
name: myapp_dev
featureFlags:
debugToolbar: trueStaging thường gần production hơn để bắt lỗi sớm:
replicaCount: 2
ingress:
host: staging.myapp.example.com
resources:
requests:
cpu: 250m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
database:
host: postgres-staging.default.svc.cluster.local
name: myapp_staging
featureFlags:
debugToolbar: falseProduction thì rõ ràng và bảo thủ hơn:
replicaCount: 4
image:
pullPolicy: Always
ingress:
host: myapp.example.com
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: "1"
memory: 1Gi
database:
host: postgres-prod.default.svc.cluster.local
name: myapp_prod
featureFlags:
debugToolbar: false💡 Cố gắng để file override càng ngắn càng tốt. Nếu một giá trị đã giống nhau ở cả 3 môi trường, hãy đưa nó về values.yaml thay vì copy đi copy lại.
Cấu hình riêng theo môi trường: resources, replicas, database, endpoints
Multi-environment không chỉ là đổi hostname. Ở đây, bạn nên xác định rõ nhóm cấu hình nào buộc phải tách ra giữa dev, staging và production.
- Replicas: dev thường 1 pod, staging 2 pod để test rollout, production 3 pod trở lên để chịu tải và tránh downtime.
- Resources: dev dùng request thấp để tiết kiệm, production phải đủ rộng để autoscaler và scheduler hoạt động ổn.
- Database: tách host, tên database, user hoặc ít nhất là schema riêng. Không dùng chung database production cho staging chỉ vì “tiện”.
- Endpoints: domain, API base URL, webhook URL và ingress annotations nên tách rõ.
Thực tế vận hành, staging là môi trường đáng đầu tư nhất. Dev có thể hơi linh hoạt, production thì nghiêm ngặt, còn staging là nơi bạn kiểm tra xem chart có hoạt động đúng trước khi promote. Nếu staging quá nhẹ, quá ít replica hoặc thiếu thành phần phụ như queue, cache, external secret sync, kết quả kiểm thử sẽ mất giá trị.
helm upgrade --install myapp ./myapp-chart \
--namespace myapp-dev \
-f values.yaml \
-f values-dev.yaml
helm upgrade --install myapp ./myapp-chart \
--namespace myapp-staging \
-f values.yaml \
-f values-staging.yaml
helm upgrade --install myapp ./myapp-chart \
--namespace myapp-prod \
-f values.yaml \
-f values-prod.yamlDùng nhiều file với thứ tự rõ ràng như trên sẽ giúp bạn nhìn đúng precedence. Lớp sau cùng thắng lớp trước. Cũng vì vậy, đừng trộn thêm quá nhiều --set trong pipeline nếu không thực sự cần. Hôm nay tiện tay thêm một flag, ba tháng sau không ai nhớ production đang khác file repo ở điểm nào.
Quản lý secrets giữa các môi trường: tách biệt, có vòng đời, không nhét vào Git
Secrets là chỗ dễ hỏng nhất trong mô hình multi-environment. Bạn không thể lấy password production copy xuống dev, cũng không nên nhét thẳng token vào values-prod.yaml. Cách đó nhanh thật, nhưng đổi lại là audit cực khó và nguy cơ lộ dữ liệu thì khỏi bàn.
Với Helm, hướng an toàn hơn là để chart chỉ tham chiếu tới Secret đã tồn tại, hoặc tích hợp với hệ thống quản lý bí mật như External Secrets Operator, Sealed Secrets, HashiCorp Vault hay cloud secret manager. Mỗi môi trường có secret backend riêng, key riêng và chính sách rotate riêng.
env:
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: myapp-db-secret
key: database_url
- name: REDIS_PASSWORD
valueFrom:
secretKeyRef:
name: myapp-redis-secret
key: passwordNếu dùng External Secrets Operator, chart của bạn chỉ cần định nghĩa nguồn lấy secret, còn giá trị thật được kéo từ backend:
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: myapp-secret
spec:
refreshInterval: 1h
secretStoreRef:
name: vault-backend
kind: ClusterSecretStore
target:
name: myapp-db-secret
data:
- secretKey: database_url
remoteRef:
key: /myapp/prod/database_url🚨 Không commit secrets dạng base64 vào Git rồi tự an ủi rằng “đã encode nên chắc an toàn”. Base64 chỉ là biểu diễn dữ liệu, không phải mã hoá.
Mẫu tích hợp CI/CD: GitOps, chart promotion và giảm thao tác tay
Khi số môi trường tăng lên, deploy thủ công bằng terminal sẽ sớm thành điểm nghẽn. Bạn vẫn có thể chạy tay lúc lab, nhưng trong hệ thống thực tế nên có pipeline rõ ràng. Có hai pattern phổ biến.
- Push trực tiếp bằng CI: pipeline chạy
helm lint, test template, rồihelm upgradevào từng môi trường. - GitOps: CI build chart/image, cập nhật manifest hoặc version trong repo môi trường, sau đó Argo CD hoặc Flux tự reconcile vào cluster.
Nếu team nhỏ, CI push trực tiếp đủ dùng. Nếu team nhiều người, cần audit tốt và muốn biết cluster luôn khớp trạng thái khai báo, GitOps đáng tiền hơn. Điểm quan trọng là chart promotion nên có thứ tự. Đừng đẩy cùng một thay đổi vào production chỉ vì build đã pass ở dev.
stages:
- lint
- package
- deploy-dev
- test
- deploy-staging
- approve
- deploy-prodMột pattern dễ áp dụng là package chart thành artifact hoặc đẩy lên OCI registry. Dev dùng chart version mới nhất sau khi lint xong. Staging chỉ nhận đúng chart đó sau khi integration test pass. Production chỉ nhận bản đã được promote, không rebuild lại giữa chừng. Làm vậy bạn tránh chuyện dev và production cùng tag phiên bản nhưng thực ra image digest khác nhau.
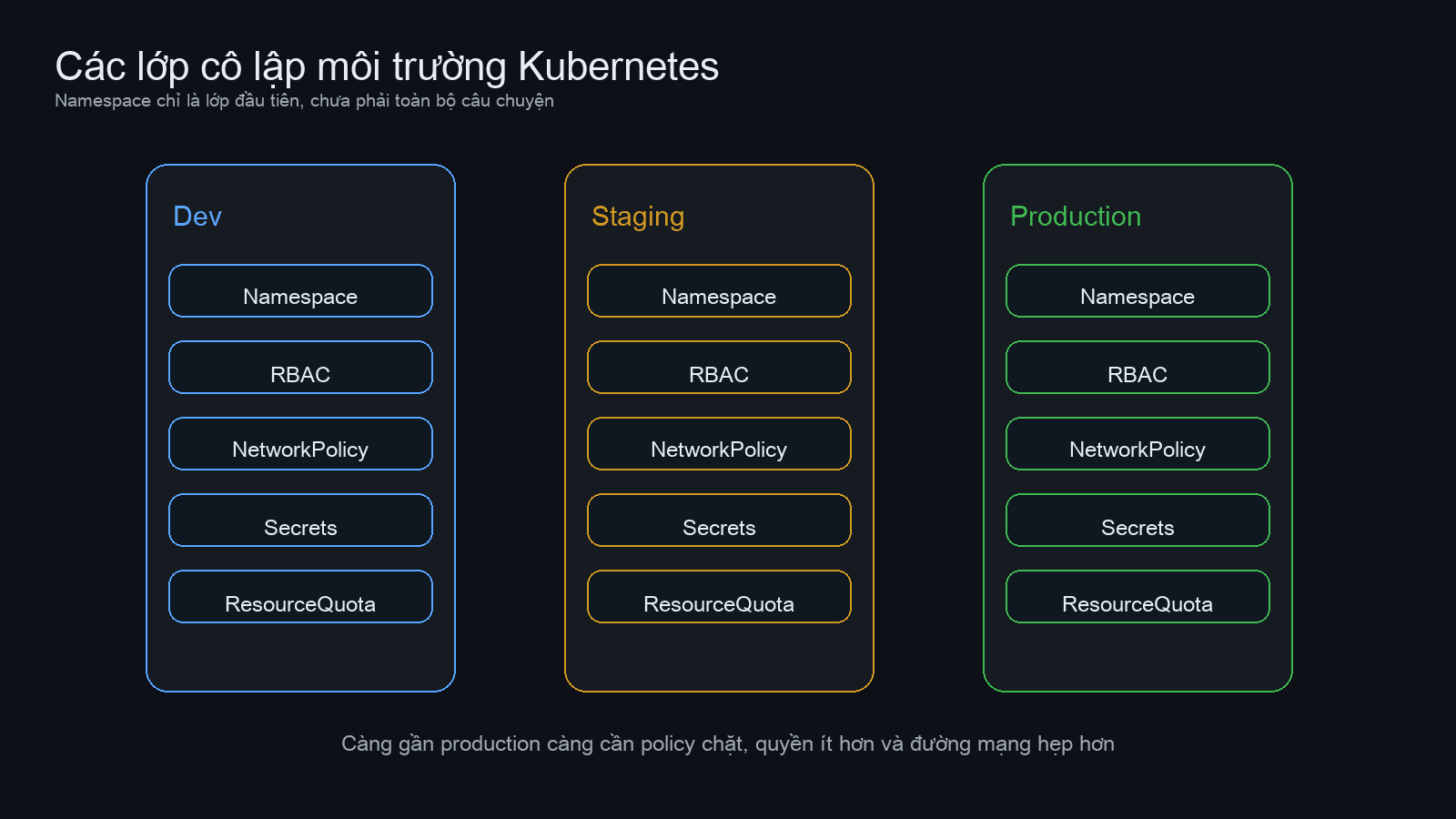
Cô lập môi trường: namespace, network policies và RBAC
Nếu chỉ đổi values mà vẫn để các môi trường nằm chung namespace, dùng chung service account và nói chuyện mạng với nhau tự do, thì bạn mới giải quyết được một nửa bài toán. Cô lập môi trường nên được làm ở nhiều lớp.
- Namespace: tối thiểu phải tách namespace dev, staging, production.
- RBAC: developer có thể thao tác dev, nhưng quyền với production cần hẹp hơn nhiều.
- NetworkPolicy: staging không nên gọi lung tung sang production, pod nội bộ cũng không nên mở toàn bộ east-west traffic.
- ResourceQuota và LimitRange: tránh một môi trường ngốn sạch tài nguyên của cluster.
Trong cluster nhỏ, đôi khi mọi người có xu hướng gom cho tiện. Nhưng đến lúc một job load test ở staging đè luôn node của production, bạn sẽ thấy “tiện” là một khoản nợ khá đắt. Namespace giúp chia logic. Network policy giúp chặn đường mạng. RBAC giúp giới hạn ai được làm gì. Ba lớp này đi cùng nhau mới đủ chắc.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-only-ingress-controller
spec:
podSelector: {}
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
app.kubernetes.io/name: ingress-nginxℹ️ Nếu production thật sự quan trọng, phương án sạch nhất vẫn là tách cluster riêng. Helm giúp tái sử dụng chart, nên tách cluster không có nghĩa là tăng gánh cấu hình quá nhiều.
Testing và validation cho từng môi trường
Multi-environment chỉ có ý nghĩa khi mỗi môi trường gắn với một lớp kiểm thử phù hợp. Dev không cần gánh mọi thứ. Production cũng không phải nơi để bạn “test nhanh một lần cuối”.
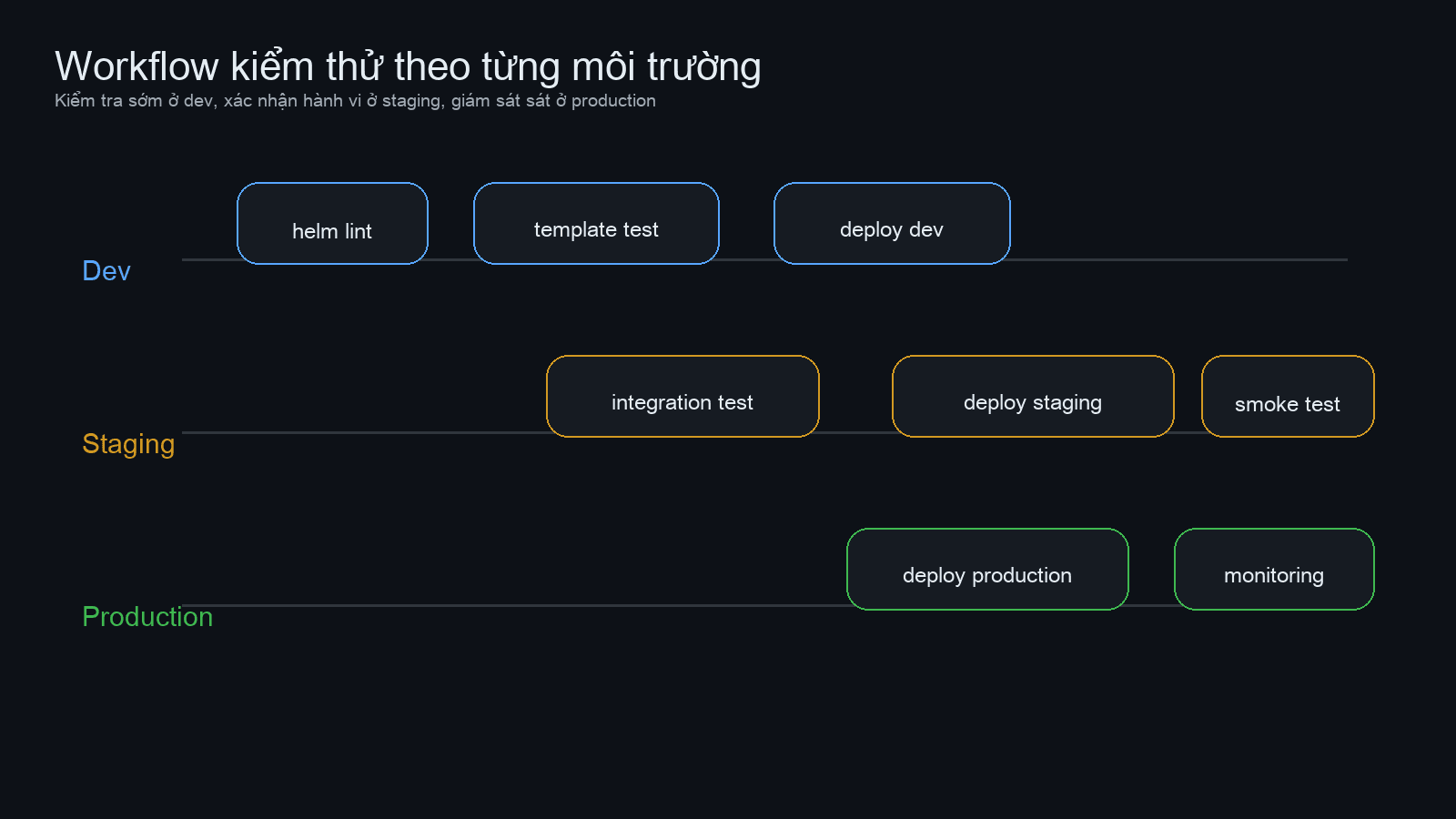
- Dev:
helm lint, render template, unit test template, deploy nhanh để developer tự kiểm tra tính năng. - Staging: integration test, smoke test, kiểm tra migration, thử rollback, xác nhận ingress và external dependencies.
- Production: deploy canary hoặc rolling update, theo dõi metrics, log, alert và kiểm tra readiness sau phát hành.
helm lint ./myapp-chart
helm template myapp ./myapp-chart -f values.yaml -f values-staging.yaml > rendered.yaml
kubectl apply --dry-run=server -f rendered.yaml
helm upgrade --install myapp ./myapp-chart -n myapp-staging -f values.yaml -f values-staging.yaml --atomic --timeout 5mMình khá thích thêm --atomic cho staging và production. Nếu rollout lỗi, Helm sẽ tự rollback release thay vì để lại trạng thái nửa sống nửa chết. Kết hợp với helm diff trước deploy, bạn sẽ nhìn được chính xác lần này đang thay đổi gì.
Một checklist validation ngắn trước khi promote production thường gồm: image tag đúng, migration tương thích ngược, probe pass, secret đã tồn tại, ingress trỏ đúng host, HPA không văng lỗi, dashboard theo dõi có số liệu và rollback path đã sẵn sàng. Nghe dài, nhưng làm thành pipeline rồi thì đỡ đau đầu hơn hẳn.
Kết lại
Helm giúp bạn mang cùng một ứng dụng đi qua nhiều môi trường mà vẫn giữ cấu trúc triển khai thống nhất. Muốn làm tốt phần này, hãy giữ values.yaml gọn, chỉ override những gì cần khác, tách secrets khỏi Git, đưa deploy vào pipeline có promotion rõ ràng, và cô lập môi trường bằng namespace, RBAC, network policy. Chừng đó chưa biến hệ thống thành hoàn hảo, nhưng đủ để giảm rất nhiều lỗi do thao tác tay và cấu hình lệch.
Nếu bạn vừa đọc xong phần 9 về production, bài này sẽ là mảnh ghép giúp chuyển từ “deploy được” sang “vận hành có quy trình”. Ở bài 11, mình sẽ nối tiếp với chủ đề umbrella chart và cách tổ chức chart cho microservices, tức phần nhiều team bắt đầu phải cân nhắc kiến trúc chart khi số service tăng nhanh.
FAQ về multi-environment deployment với Helm
Có nên dùng một chart cho cả dev, staging và production không?
Phần lớn trường hợp là có. Một chart chung giúp bạn giữ logic triển khai nhất quán. Khác biệt giữa môi trường nên được đẩy xuống values và policy, không nên fork chart quá sớm.
Khi nào nên tách chart riêng?
Khi kiến trúc triển khai đã khác bản chất, ví dụ production có thêm worker, sidecar, service mesh hook hoặc policy mà dev hoàn toàn không dùng. Nếu chỉ khác replicas, domain hay resources thì chưa cần tách chart.
Secrets nên để ở đâu?
Nên để ở secret manager hoặc hệ thống đồng bộ secrets như Vault, External Secrets Operator, Sealed Secrets. Không nên commit trực tiếp vào Git dưới dạng plain text hoặc base64.
Staging cần giống production đến mức nào?
Càng giống về topology, policy và hành vi chart càng tốt. Không nhất thiết giống 100% về dữ liệu hay quy mô tài nguyên, nhưng đủ gần để kiểm thử có ý nghĩa.
Có nên dùng --set thay cho file values không?
Chỉ nên dùng cho override rất nhỏ hoặc giá trị động sinh trong pipeline. Cấu hình chính vẫn nên nằm trong file để dễ review, dễ audit và dễ tái hiện.
Có thể bạn cần xem thêm
- NodeJS Full-Stack trong Helm phần 1: Kiến trúc chart cho React/Next.js + Express (Phần 7/11)
- NodeJS Full-Stack trong Helm phần 2: Thêm PostgreSQL + Redis dependencies (Phần 8/11)
- Tự đóng gói ứng dụng Node.js cơ bản thành Helm chart (Phần 6/11)
- Cài đặt Helm và dựng lab Kubernetes local với kind/OrbStack (Phần 2/11)
- Deploy ứng dụng từ public repository: Bitnami, Artifact Hub và best practices (Phần 5/11)
- Umbrella chart vs microservices strategy: Khi nào dùng cách nào (Phần 11/11)
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.