
Khi nghe về AI, bạn thường gặp hai thuật ngữ được nhắc đến nhiều: Machine Learning (máy học) và Deep Learning (học sâu). Nhiều người nghĩ chúng giống nhau hoặc Deep Learning chỉ là phiên bản “nâng cấp” của Machine Learning. Thực tế, mối quan hệ giữa chúng phức tạp hơn thế.
Bài viết này sẽ giải thích rõ ràng sự khác biệt giữa Deep Learning và Machine Learning, khi nào nên dùng cái nào, và tại sao Deep Learning lại cần GPU để hoạt động hiệu quả. Đặc biệt quan trọng với những ai đang cân nhắc triển khai AI trong doanh nghiệp.
Deep Learning là gì?
Deep Learning (học sâu) là một nhánh chuyên biệt của Machine Learning, sử dụng mạng nơ-ron nhân tạo (neural networks) với nhiều lớp để mô phỏng cách thức hoạt động của bộ não con người.
Điểm khác biệt chính: Deep Learning có thể tự động tìm ra các “đặc trưng” (features) quan trọng từ dữ liệu thô, trong khi Machine Learning truyền thống thường cần con người chỉ ra những đặc trưng này.
Mối quan hệ AI – ML – DL
Hãy tưởng tượng như các vòng tròn lồng nhau:
- AI (Trí tuệ nhân tạo) – Vòng tròn lớn nhất
- Machine Learning – Một phần của AI
- Deep Learning – Một phần của Machine Learning
Nói cách khác: Tất cả Deep Learning đều là Machine Learning, nhưng không phải tất cả Machine Learning đều là Deep Learning.
So sánh chi tiết: Deep Learning vs Machine Learning
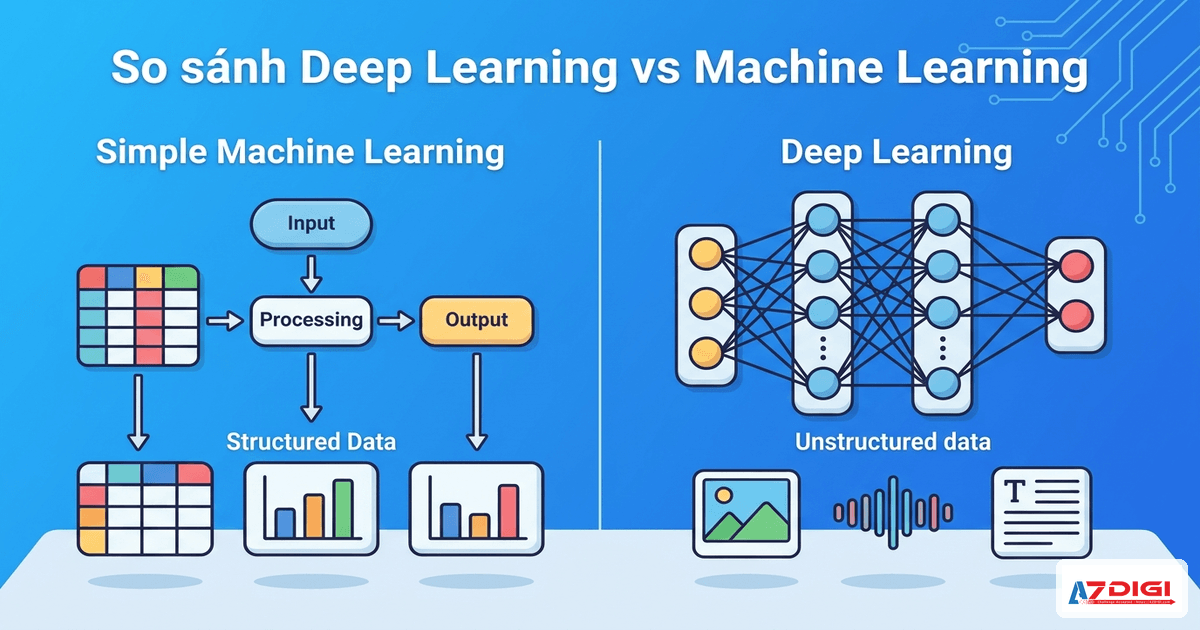
1. Cách xử lý dữ liệu
Machine Learning truyền thống có cách tiếp cận thủ công trong việc xử lý dữ liệu. Các chuyên gia phải làm feature engineering thủ công, nghĩa là chỉ ra cho máy tính những đặc trưng nào cần chú ý. Ví dụ khi phân loại ảnh, bạn phải nói rõ “hãy chú ý đến màu sắc, kích thước, hình dạng”. Machine Learning truyền thống hoạt động tốt nhất với dữ liệu có cấu trúc rõ ràng như bảng Excel, file CSV hay database.
Deep Learning ngược lại có khả năng tự động tìm ra những đặc trưng quan trọng từ dữ liệu. Bạn chỉ cần đưa dữ liệu thô vào, mạng nơ-ron sẽ tự học cần chú ý những gì mà không cần con người chỉ định. Đây là lý do Deep Learning xuất sắc khi xử lý dữ liệu phi cấu trúc như hình ảnh, âm thanh, video hay văn bản tự do.
2. Yêu cầu về dữ liệu
Machine Learning truyền thống hoạt động tốt ngay cả khi bạn chỉ có vài nghìn đến vài vạn mẫu dữ liệu. Đây là lợi thế lớn cho các doanh nghiệp vừa và nhỏ, nơi việc thu thập hàng triệu samples không khả thi. Với dataset nhỏ, các thuật toán như Random Forest hay XGBoost vẫn cho kết quả ổn định mà ít bị overfitting.
Deep Learning ngược lại đòi hỏi lượng dữ liệu khổng lồ, từ hàng triệu đến hàng tỷ mẫu dữ liệu. Càng có nhiều dữ liệu, hiệu suất của Deep Learning càng tốt. Tuy nhiên, nếu dữ liệu quá ít, Deep Learning dễ bị overfitting nghiêm trọng – model học thuộc lòng dữ liệu training mà không tổng quát hóa được cho dữ liệu mới.
3. Sức mạnh tính toán
Machine Learning truyền thống rất thân thiện với tài nguyên tính toán. Các thuật toán ML có thể chạy mượt mà trên CPU thông thường mà không cần phần cứng chuyên dụng. Thời gian training cũng ngắn, chỉ từ vài phút đến vài giờ là hoàn thành. Điều này giúp tiết kiệm đáng kể chi phí điện năng và phần cứng.
Deep Learning ngược lại đòi hỏi sức mạnh tính toán khủng khiếp. Để training hiệu quả, bạn cần GPU hoặc TPU chuyên dụng thay vì CPU thông thường. Thời gian training có thể kéo dài từ vài giờ đến vài tuần, thậm chí vài tháng đối với model lớn. Điều này dẫn đến chi phí điện năng và tài nguyên rất cao.
Để training Deep Learning hiệu quả, bạn cần GPU VPS chuyên dụng thay vì máy chủ CPU thường.
4. Khả năng giải thích (Interpretability)
Machine Learning truyền thống có ưu điểm lớn về tính minh bạch. Bạn có thể hiểu rõ tại sao model đưa ra quyết định cụ thể, ví dụ “khách hàng được chấp thuận vay vì thu nhập trên 50 triệu đồng và không có nợ xấu”. Khả năng truy vết lý do quyết định này rất quan trọng trong các ngành có quy định nghiêm ngặt như tài chính, y tế hay bảo hiểm.
Deep Learning lại là một “hộp đen” khó giải thích. Bạn chỉ biết input và output, nhưng không hiểu tại sao model lại đưa ra kết quả đó. Quy trình xử lý bên trong neural network quá phức tạp để con người theo dõi. Đây trở thành thách thức lớn khi triển khai Deep Learning trong môi trường doanh nghiệp, đặc biệt là những ngành cần compliance cao.
Kiến trúc Neural Networks trong Deep Learning
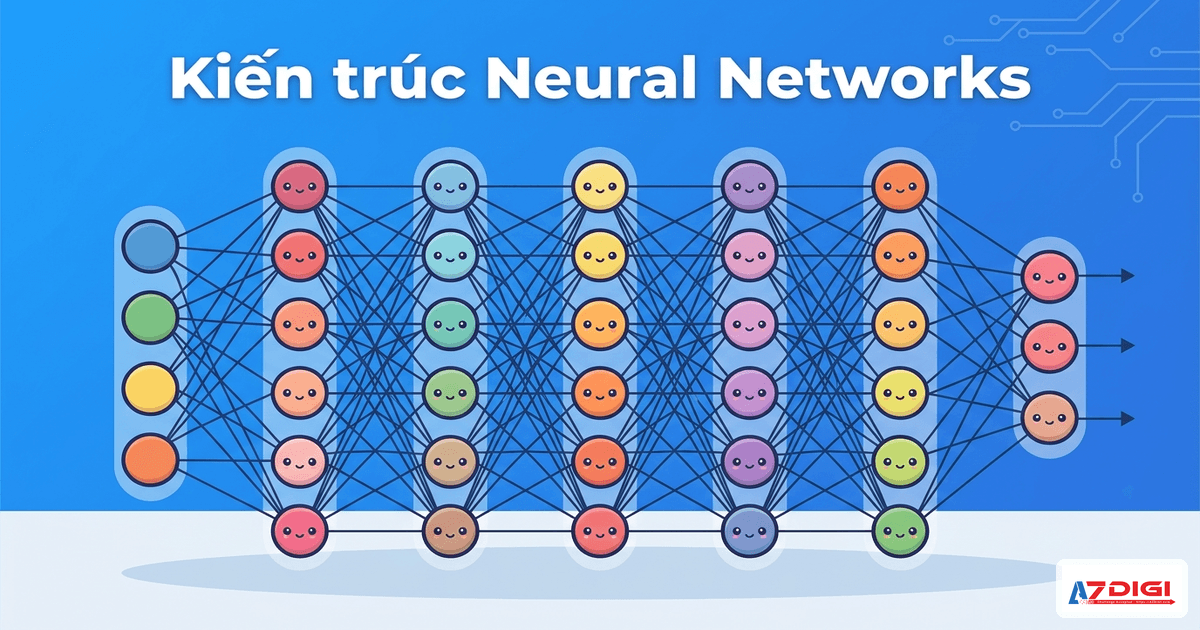
Deep Learning dựa trên mạng nơ-ron nhân tạo với cấu trúc nhiều lớp:
Cấu trúc cơ bản
- Input Layer (Lớp đầu vào): Nhận dữ liệu thô
- Hidden Layers (Lớp ẩn): Từ 3 lớp trở lên (có thể hàng trăm lớp)
- Output Layer (Lớp đầu ra): Cho kết quả cuối cùng
Mỗi lớp học một level trừu tượng khác nhau:
- Lớp 1: Phát hiện cạnh, góc cơ bản
- Lớp 2: Nhận dạng hình dạng đơn giản
- Lớp 3: Nhận dạng các bộ phận (mắt, mũi)
- Lớp 4: Nhận dạng khuôn mặt hoàn chỉnh
Các loại Deep Learning phổ biến
1. Convolutional Neural Networks (CNN)
Chuyên dụng cho: Xử lý hình ảnh và computer vision
CNN hoạt động bằng cách sử dụng các “filter” quét qua toàn bộ hình ảnh. Mỗi filter được thiết kế để học một pattern cụ thể như edge detection, texture recognition hay shape detection. Sau đó, pooling layer sẽ giảm kích thước ảnh xuống nhưng vẫn giữ lại những thông tin quan trọng nhất, giúp model hiệu quả hơn trong việc xử lý.
Ứng dụng:
- Nhận diện khuôn mặt (Facebook tag ảnh)
- Phân loại ảnh y tế (X-ray, MRI)
- Xe tự lái nhận dạng vật cản
- Kiểm tra chất lượng sản phẩm tự động
2. Recurrent Neural Networks (RNN)
Chuyên dụng cho: Dữ liệu tuần tự (text, speech, time series)
RNN có đặc điểm độc đáo là sở hữu “memory” để nhớ thông tin từ các bước xử lý trước đó. Khác với CNN xử lý toàn bộ ảnh cùng lúc, RNN xử lý từng phần tử một theo thứ tự thời gian. LSTM và GRU là những phiên bản cải tiến của RNN, khắc phục được vấn đề vanishing gradient và có thể nhớ thông tin dài hạn tốt hơn.
RNN và LSTM đang dần bị thay thế bởi Transformer và SSM trong nhiều ứng dụng. Tuy nhiên, RNN vẫn phù hợp cho các thiết bị edge có tài nguyên hạn chế.
Ứng dụng:
- Dịch thuật (Google Translate)
- Nhận dạng giọng nói (Siri, Alexa)
- Dự đoán giá cổ phiếu
- Tạo văn bản tự động
3. Transformers
Chuyên dụng cho: Xử lý ngôn ngữ tự nhiên (NLP)
Transformer mang đến đột phá với “attention mechanism” – khả năng chú ý vào những phần quan trọng trong dữ liệu. Thay vì xử lý tuần tự như RNN, Transformer có thể xử lý song song, giúp tăng tốc độ training đáng kể. Đây chính là nền tảng của GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro và hầu hết các Large Language Models hiện đại năm 2026.
Tuy nhiên, tính đến 2026, Transformer không còn là kiến trúc duy nhất. State Space Models (SSM) như Mamba 3 (ra 3/2026, chấp nhận tại ICLR 2026) đã chứng minh tốc độ inference nhanh hơn Transformer tới 7 lần với chi phí thấp hơn đáng kể. Kiến trúc hybrid kết hợp Transformer + SSM đang trở thành xu hướng mới.
Hơn 60% model tiên tiến phát hành năm 2025 sử dụng Mixture of Experts (MoE). DeepSeek-V3 có 671 tỷ tham số nhưng chỉ kích hoạt 37 tỷ mỗi token, giảm chi phí training tới 90%.
Ứng dụng:
- ChatGPT, Claude, Gemini
- Dịch thuật chất lượng cao
- Tóm tắt văn bản tự động
- Code generation
4. Generative Adversarial Networks (GANs)
Chuyên dụng cho: Tạo nội dung mới
GAN hoạt động theo cơ chế “đối nghịch” giữa hai mạng neural network. Generator có nhiệm vụ tạo ra nội dung giả, trong khi Discriminator cố gắng phát hiện nội dung nào là giả. Hai mạng này “thi đấu” và học hỏi lẫn nhau, cuối cùng Generator trở nên tinh vi đến mức có thể tạo ra nội dung gần như không thể phân biệt với thật.
Ứng dụng:
- Deepfake (tạo video giả)
- Tạo ảnh nghệ thuật (DALL-E)
- Nâng cấp chất lượng ảnh
- Tạo dữ liệu synthetic
5. State Space Models (SSM/Mamba)
Kiến trúc mới, thay thế Transformer cho một số tác vụ. Xử lý sequence với độ phức tạp tuyến tính O(N) thay vì bậc hai O(N²) như Transformer. Mamba 3 (3/2026) nhanh hơn Transformer 7 lần khi inference.
Phù hợp cho:
- Xử lý sequence dài (genomics, time series)
- Inference tiết kiệm năng lượng
- Thiết bị edge
Khi nào nên dùng Deep Learning?
Dùng Deep Learning khi:
- Dữ liệu phi cấu trúc: Hình ảnh, video, âm thanh, văn bản tự do
- Dữ liệu lớn: Hàng triệu samples trở lên
- Pattern phức tạp: Mối quan hệ phi tuyến tính cao
- Tự động hóa feature extraction: Không muốn làm feature engineering thủ công
- Có GPU/TPU: Đủ sức mạnh tính toán
- Không cần giải thích: Chấp nhận “black box” để đổi lấy hiệu suất
Ví dụ phù hợp:
- Nhận diện khuôn mặt trong camera an ninh
- Chẩn đoán bệnh qua ảnh X-ray
- Chatbot thông minh
- Xe tự lái
- Dịch thuật tự động
- Recommend system phức tạp
Khi nào nên dùng Machine Learning truyền thống?
Dùng ML truyền thống khi:
- Dữ liệu có cấu trúc: Bảng, CSV, database
- Dữ liệu ít: Vài nghìn đến vài vạn samples
- Cần giải thích: Phải hiểu tại sao model đưa ra quyết định đó
- Tài nguyên hạn chế: Chỉ có CPU thường
- Cần kết quả nhanh: Training trong vài giờ
- Problem đơn giản: Mối quan hệ tuyến tính hoặc phi tuyến đơn giản
Ví dụ phù hợp:
- Dự đoán giá nhà dựa trên diện tích, vị trí
- Phân loại email spam đơn giản
- Dự báo doanh số dựa trên lịch sử
- Credit scoring trong ngân hàng
- A/B testing analysis
- Customer segmentation
Ứng dụng thực tế Deep Learning vs Machine Learning
Netflix recommendation
Machine Learning approach:
- Features thủ công: thể loại, diễn viên, năm sản xuất
- Collaborative filtering đơn giản
- Ma trận user-item factorization
Deep Learning approach:
- Neural networks học từ hành vi xem phức tạp
- Phân tích nội dung video để extract features tự động
- Multi-modal: kết hợp text, images, viewing patterns
Fraud detection ngân hàng
Machine Learning approach:
- Rules-based: số tiền, thời gian, địa điểm giao dịch
- Random Forest, Logistic Regression
- Dễ giải thích cho regulator
Deep Learning approach:
- Phân tích sequence giao dịch phức tạp
- Phát hiện fraud pattern tinh vi
- Nhưng khó giải thích cho khách hàng tại sao bị block
Để hiểu sâu hơn về Machine Learning, bạn có thể đọc bài “Machine Learning là gì? Giải thích đơn giản cho người không chuyên”.
Yêu cầu hạ tầng cho Deep Learning

Tại sao Deep Learning cần GPU?
Deep Learning thực hiện hàng triệu (hoặc tỷ) phép tính song song. GPU có hàng nghìn nhân xử lý nhỏ, lý tưởng cho:
- Matrix operations: Neural networks về bản chất là chuỗi phép nhân ma trận
- Parallel processing: Tính toán nhiều neurons cùng lúc
- Memory bandwidth: GPU có băng thông cao hơn CPU 10-20 lần
Training model Deep Learning trên CPU có thể chậm hơn GPU 50-100 lần!
GPU 2026 cho Deep Learning
GPU cho Deep Learning hiện tại dùng NVIDIA H100 (80GB HBM3), H200 (141GB HBM3e), B200 (192GB HBM3e). Với VPS giá rẻ thì GPU entry-level thường là RTX 4090 (24GB) hoặc A100 (40/80GB).
| GPU | VRAM | Giá cloud (~) | Phù hợp |
|---|---|---|---|
| RTX 4090 | 24GB | $0.40-0.65/h | Thử nghiệm, fine-tuning model nhỏ |
| A100 | 80GB | $1.79/h | Training model tầm trung |
| H100 | 80GB | $2-4/h | Production, training model lớn |
| H200 | 141GB | $3.70-5/h | Model 70B+, long context |
Lựa chọn hạ tầng
Để triển khai Deep Learning hiệu quả, AZDIGI cung cấp:
- GPU VPS: Chuyên dụng training Deep Learning với GPU hiện đại
- AMD Cloud Server: CPU mạnh cho ML truyền thống
- NVMe Storage: Tốc độ đọc/ghi dữ liệu nhanh
- High RAM: Load dataset lớn vào memory
So sánh chi phí
Machine Learning truyền thống:
- CPU server từ 99k/tháng đã đủ dùng
- Training trong vài giờ
- Chi phí điện thấp
Deep Learning:
- GPU server từ 590k/tháng
- Training từ ngày đến tuần
- Chi phí điện cao hơn đáng kể
Thách thức và hạn chế
Deep Learning challenges
- Data hungry: Cần rất nhiều dữ liệu quality
- Computational expensive: Tốn kém về GPU/electricity
- Black box: Khó giải thích quyết định
- Overfitting: Dễ học “thuộc lòng” training data
- Hyperparameter tuning: Nhiều tham số cần điều chỉnh
- Model drift: Performance giảm theo thời gian
Machine Learning truyền thống challenges
- Feature engineering: Tốn thời gian làm features thủ công
- Limited capability: Không xử lý được dữ liệu phức tạp
- Manual process: Cần domain expertise để thiết kế features
- Scaling issues: Khó mở rộng với dữ liệu lớn
Xu hướng tương lai
AutoML – Tự động hóa Machine Learning
AutoML đang bridge gap giữa ML và DL:
- Tự động feature engineering
- Tự động chọn model tối ưu
- Tự động hyperparameter tuning
- Dễ sử dụng cho non-experts
Google AutoML, H2O.ai, và các nền tảng no-code AI đang giúp doanh nghiệp vừa và nhỏ triển khai ML mà không cần team data science chuyên sâu.
Explainable AI (XAI)
Giải quyết vấn đề “black box” của Deep Learning:
- LIME, SHAP để giải thích predictions
- Attention visualization
- Model interpretability tools
Apple đang đổi tên Core ML thành Core AI (dự kiến WWDC 2026), tích hợp mô hình nền tảng on-device với khả năng giải thích kết quả.
Edge AI
Chạy Deep Learning trực tiếp trên device:
- Model compression techniques
- Quantization để giảm kích thước model
- Specialized chips (TPU, Neural Processing Units)
2026 được coi là điểm bùng nổ Edge AI. NPU (Neural Processing Unit) trên smartphone đạt hiệu suất 10-100 lần tốt hơn CPU thông thường cho inference.
Apple M5 chip với NPU 16 nhân, Qualcomm Snapdragon 8 Elite với 75 TOPS (nghìn tỷ phép tính/giây)
Small Language Models (SLMs) dưới 3 tỷ tham số chạy trực tiếp trên điện thoại, không cần cloud
Meta ExecuTorch 1.0 (1/2026): runtime chỉ 50KB giúp chạy AI inference trên smartphone
Kiến trúc mới 2026
Kiến trúc hybrid (Transformer + SSM + MoE) đang trở thành tiêu chuẩn mới cho model tiên tiến
Diffusion Language Models: LLaDA (8B params) xử lý text như denoising thay vì dự đoán token tuần tự, đạt tốc độ 1,479 tokens/giây (Gemini Diffusion)
Để có cái nhìn tổng quan về AI, hãy đọc bài “AI là gì? Phân loại, cách hoạt động và 10 ứng dụng thực tế”.
Ứng dụng mới 2026:
- Dịch thuật (Google Translate)
- Nhận dạng giọng nói (Siri, Alexa)
- AI Agent tự động hóa workflow (n8n, Claude Computer Use, GPT-5.4 Computer Use API)
Deep Learning có phải lúc nào cũng tốt hơn Machine Learning không?
Không. Deep Learning tốt hơn với dữ liệu lớn, phi cấu trúc (ảnh, video, text) và pattern phức tạp. Machine Learning truyền thống tốt hơn với dữ liệu nhỏ, có cấu trúc, cần giải thích kết quả và tài nguyên hạn chế.
Tại sao Deep Learning cần GPU mà Machine Learning không?
Deep Learning sử dụng neural networks với hàng triệu tham số, cần tính toán song song hàng nghìn phép toán ma trận. GPU có hàng nghìn cores nhỏ, phù hợp cho tính toán song song. Machine Learning truyền thống có ít tham số hơn, CPU thường đã đủ mạnh.
CNN, RNN và Transformer khác nhau như thế nào?
CNN chuyên xử lý hình ảnh bằng filter quét qua ảnh. RNN xử lý dữ liệu tuần tự (text, speech) có memory nhớ thông tin trước. Transformer dùng attention mechanism, xử lý song song, là nền tảng của ChatGPT và các LLM hiện đại.
Deep Learning có thể chạy mà không cần Internet không?
Có, sau khi training xong, model có thể chạy offline (inference). Ví dụ: nhận diện khuôn mặt trên iPhone, Google Translate offline. Edge AI đang phát triển mạnh để chạy Deep Learning trực tiếp trên thiết bị.
Feature engineering trong ML và DL khác nhau thế nào?
Machine Learning truyền thống cần con người làm feature engineering thủ công, chỉ ra cho máy nên chú ý gì. Deep Learning tự động extract features từ dữ liệu thô thông qua các lớp neural network, không cần con người thiết kế features.
Kết luận
Deep Learning và Machine Learning không phải là “đối thủ” mà là các công cụ khác nhau phục vụ các mục đích khác nhau. Deep Learning xuất sắc với dữ liệu phi cấu trúc và pattern phức tạp, nhưng đòi hỏi nhiều tài nguyên. Machine Learning truyền thống hiệu quả với dữ liệu có cấu trúc và cần tính minh bạch.
Việc lựa chọn công nghệ nào phụ thuộc vào:
- Loại và lượng dữ liệu bạn có
- Độ phức tạp của bài toán
- Tài nguyên tính toán available
- Yêu cầu về tính minh bạch
- Thời gian và budget
Hiểu rõ điểm mạnh, yếu của từng approach sẽ giúp bạn đưa ra quyết định đúng đắn. Và nếu quyết định triển khai Deep Learning, hãy đảm bảo có đủ hạ tầng mạnh mẽ như GPU VPS của AZDIGI để tận dụng tối đa sức mạnh của công nghệ này.
Tiếp tục khám phá thế giới AI với Claude Code và chuẩn bị cho tương lai số hóa đang đến rất gần!
Có thể bạn cần xem thêm
- Neural Network là gì? Cách mạng nơ-ron nhân tạo "học" từ dữ liệu
- AI là gì? Phân loại, cách hoạt động và 10 ứng dụng thực tế
- Generative AI: công nghệ đứng sau ChatGPT, Gemini và làn sóng AI tạo sinh
- vLLM là gì? Khi nào nên dùng vLLM thay Ollama
- Flow trong CrewAI: xây dựng workflow phức tạp theo sự kiện
- Gemma 4 là gì? Model AI mở mạnh nhất của Google chạy từ điện thoại đến server
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.