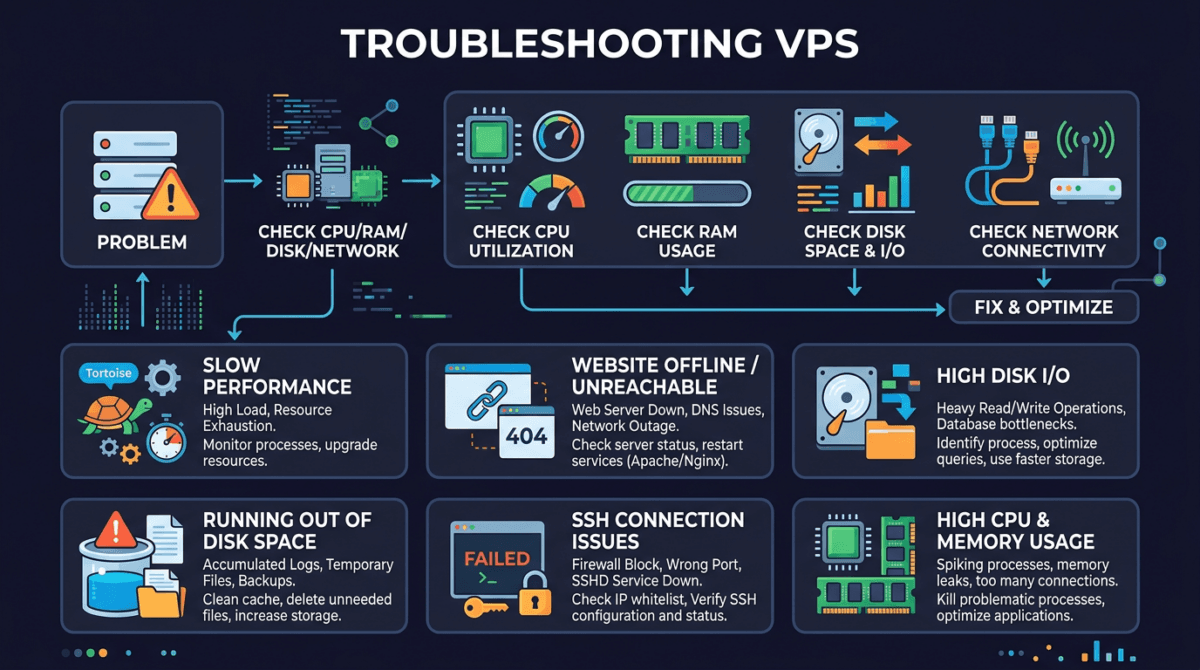
Đang yên đang lành, website sập. SSH vào không được. Khách hàng gọi điện liên tục. Bạn mở terminal lên và… không biết bắt đầu từ đâu.
📚 Bài này thuộc Serie Quản trị VPS Linux.
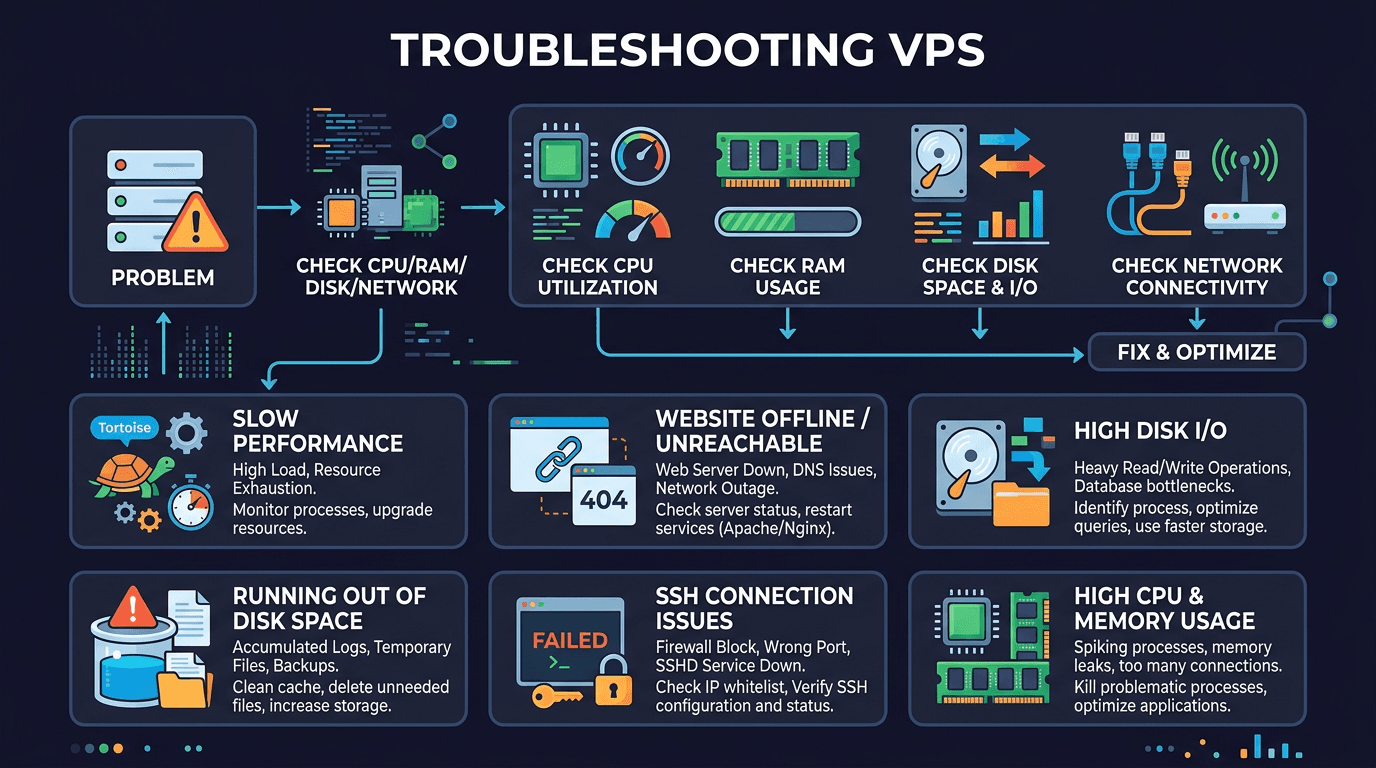
Nếu đã từng rơi vào tình huống này, bạn không phải người duy nhất. Troubleshooting là kỹ năng mà ai quản trị VPS cũng cần, nhưng ít ai được dạy bài bản. Phần lớn mọi người xử lý sự cố theo kiểu “thử cái này xem”, restart lung tung, rồi may mắn thì hết lỗi, không may thì càng rối hơn.
Bài này mình sẽ đi qua 6 sự cố phổ biến nhất khi vận hành VPS Linux, kèm theo cách tiếp cận có hệ thống để bạn không phải đoán mò mỗi khi server “dở chứng”.
Tư duy troubleshooting: đừng đoán, hãy kiểm tra
Trước khi đi vào từng sự cố cụ thể, mình muốn nói về cách tiếp cận. Vì nếu bạn có phương pháp đúng, dù gặp sự cố gì cũng xử lý được. Ngược lại, không có phương pháp thì dù lỗi đơn giản cũng loay hoay cả tiếng.
Quy trình troubleshooting chuẩn gồm 6 bước:
- Xác định triệu chứng, Cái gì đang hỏng? Lỗi cụ thể là gì? Xảy ra từ khi nào?
- Thu thập dữ liệu, Kiểm tra log, metrics, trạng thái dịch vụ. Đừng giả định, hãy đọc số liệu thực tế.
- Đặt giả thuyết, Dựa trên data đã thu thập, nguyên nhân có thể là gì?
- Kiểm tra giả thuyết, Test từng giả thuyết một. Mỗi lần chỉ thay đổi một thứ.
- Áp dụng fix, Khi đã xác định đúng nguyên nhân, fix nó.
- Verify, Kiểm tra lại xem sự cố đã thực sự hết chưa. Đừng fix xong rồi bỏ đi.
Nguyên tắc vàng: mỗi lần chỉ thay đổi một thứ. Nếu bạn thay đổi 3 thứ cùng lúc rồi sự cố hết, bạn sẽ không biết cái nào thực sự fix được vấn đề. Lần sau gặp lại thì vẫn mò.
Nghe thì đơn giản, nhưng khi server đang sập và áp lực đè lên, rất dễ bỏ qua quy trình để “thử nhanh cho lẹ”. Hãy cưỡng lại cái cám dỗ đó.
Sự cố 1: VPS không SSH được
Đây là sự cố kinh điển và cũng là cái đáng sợ nhất, vì khi không SSH được thì bạn gần như bị “khóa ngoài cửa”. Nhưng đừng hoảng, cứ đi theo từng bước.
Bước 1: VPS có đang chạy không?
Nghe buồn cười nhưng đôi khi VPS đơn giản là đã tắt. Đăng nhập vào panel của nhà cung cấp (DigitalOcean, Vultr, Linode, hay bất kỳ provider nào bạn dùng) để kiểm tra trạng thái. Nếu VPS đang off, bật lên. Nếu đang “running” mà vẫn không SSH được, dùng VNC/Console trên panel để truy cập trực tiếp.
Bước 2: Kiểm tra sshd có đang chạy
Nếu bạn truy cập được qua console của provider, việc đầu tiên là kiểm tra dịch vụ SSH:
systemctl status sshd # CentOS/AlmaLinux/Rocky
systemctl status ssh # Ubuntu/DebianNếu dịch vụ đã dừng, khởi động lại:
systemctl start sshd # CentOS/AlmaLinux/Rocky
systemctl start ssh # Ubuntu/DebianCũng nên kiểm tra xem sshd có listen đúng port không:
ss -tlnp | grep sshOutput bình thường sẽ hiển thị sshd đang listen trên port 22 (hoặc port tùy chỉnh nếu bạn đã đổi). Nếu không thấy gì, kiểm tra lại config tại /etc/ssh/sshd_config xem có lỗi cú pháp không:
sshd -tLệnh này sẽ báo lỗi cú pháp nếu có. Fix lỗi rồi restart lại sshd.
Bước 3: Firewall có đang block không?
Firewall là thủ phạm phổ biến. Kiểm tra bằng:
# UFW (Ubuntu/Debian)
ufw status
# firewalld (CentOS/AlmaLinux/Rocky)
firewall-cmd --list-all
# iptables (cả hai)
iptables -L -n | grep 22
Nếu port SSH bị block, mở lại:
# UFW
ufw allow 22/tcp
# firewalld
firewall-cmd --permanent --add-service=ssh
firewall-cmd --reload
Ngoài firewall trên VPS, đừng quên kiểm tra Security Group hoặc firewall ở tầng provider nữa. Một số nhà cung cấp như AWS, GCP có firewall riêng ở ngoài VPS.
Bước 4: IP bị ban bởi fail2ban?
Nếu bạn có cài fail2ban (mà nên cài), rất có thể IP của bạn bị ban do nhập sai mật khẩu quá nhiều lần:
# Kiểm tra danh sách IP bị ban
fail2ban-client status sshd
# Unban IP của bạn
fail2ban-client set sshd unbanip YOUR_IP
Mẹo: Thêm IP cố định của bạn vào whitelist trong /etc/fail2ban/jail.local (dòng ignoreip) để không bao giờ bị ban nhầm. Nếu IP động, dùng SSH key thay vì password thì fail2ban sẽ không ảnh hưởng.
📖 Liên quan: SSH Key · SSH Hardening · Fail2ban · SSH qua Tailscale
Sự cố 2: Website không truy cập được
Khách báo website lỗi 502, 503, hoặc không load được gì. Đây là lúc bạn cần kiểm tra từ ngoài vào trong.
Bước 1: DNS có resolve đúng không?
Trước khi đào sâu vào server, kiểm tra xem DNS có trỏ đúng IP không đã:
dig yourdomain.com +short
# hoặc
nslookup yourdomain.comNếu IP trả về không đúng hoặc không có kết quả, vấn đề nằm ở DNS chứ không phải server. Kiểm tra lại bản ghi DNS ở nơi quản lý domain.
Bước 2: Web server có đang chạy không?
# Nginx
systemctl status nginx
# Apache
systemctl status httpd # CentOS/AlmaLinux/Rocky
systemctl status apache2 # Ubuntu/Debian
Nếu dịch vụ đã dừng, kiểm tra lý do trước khi restart:
# Xem log lỗi gần nhất
journalctl -u nginx --no-pager -n 30
journalctl -u httpd --no-pager -n 30 # CentOS/AlmaLinux/Rocky
journalctl -u apache2 --no-pager -n 30 # Ubuntu/DebianMột lý do phổ biến khiến web server không start được là lỗi cú pháp trong config:
# Test config trước khi restart
nginx -t
apachectl configtestBước 3: Port 80/443 có đang listen?
ss -tlnp | grep -E ':80|:443'Nếu không có gì listen trên port 80 hoặc 443, web server chưa chạy hoặc đang listen port khác. Kiểm tra lại config web server.
Bước 4: Firewall có mở port web?
# UFW
ufw status | grep -E '80|443'
# firewalld
firewall-cmd --list-services | grep -E 'http|https'
Bước 5: SSL certificate hết hạn?
Nếu website HTTP vẫn vào được nhưng HTTPS thì báo lỗi, khả năng cao SSL cert đã hết hạn:
# Kiểm tra ngày hết hạn cert
echo | openssl s_client -connect yourdomain.com:443 -servername yourdomain.com 2>/dev/null | openssl x509 -noout -datesNếu dùng Let’s Encrypt, renew bằng:
certbot renew
systemctl reload nginx # hoặc httpd/apache2Đặt cron job tự động renew Let’s Encrypt cert để không bao giờ bị hết hạn bất ngờ. Bài trước trong series đã hướng dẫn cách setup cron, bạn nên áp dụng luôn cho việc này.
📖 Liên quan: Firewall UFW/firewalld · Networking cơ bản · Systemd quản lý service
Sự cố 3: VPS chậm, lag
VPS chạy được nhưng mọi thứ đều chậm. SSH gõ lệnh delay, website load mãi không xong. Lúc này cần xác định “nút cổ chai” nằm ở đâu: CPU, RAM, Disk hay Network.
Kiểm tra CPU
# Xem tổng quan nhanh
top -bn1 | head -20
# Hoặc dùng htop cho dễ đọc hơn
htop
Nhìn vào dòng %Cpu(s). Nếu us (user) cao, có process đang ngốn CPU. Nhìn xuống danh sách process bên dưới để tìm thủ phạm. Nếu wa (I/O wait) cao, vấn đề nằm ở disk chứ không phải CPU.
Kiểm tra RAM
free -hChú ý cột available. Nếu available gần bằng 0, hệ thống đang thiếu RAM nghiêm trọng. Khi đó Linux sẽ dùng swap (chậm hơn nhiều lần so với RAM), hoặc tệ hơn là kích hoạt OOM Killer để “giết” process.
Kiểm tra xem OOM Killer đã từng hoạt động chưa:
dmesg | grep -i "oom\|out of memory"
journalctl | grep -i "oom\|out of memory"Nếu thấy log OOM Killer, bạn cần tìm process nào đang ăn nhiều RAM nhất:
ps aux --sort=-%mem | head -10Kiểm tra Disk I/O
# Cần cài gói sysstat
iostat -x 1 5Nhìn cột %util. Nếu gần 100%, disk đang quá tải. Cột await cho biết thời gian chờ trung bình (ms) của mỗi I/O request. Giá trị cao (trên 20ms với SSD) cho thấy disk đang bị nghẽn.
Kiểm tra Network
# Xem bandwidth realtime
iftop
# Hoặc xem thống kê tổng quan
vnstat
Nếu bandwidth đang cao bất thường, có thể VPS đang bị DDoS hoặc có process nào đó đang gửi/nhận data lớn.
Tìm process ngốn tài nguyên
Khi đã xác định được nút cổ chai (CPU, RAM hay Disk), tìm process chịu trách nhiệm:
# Top 10 process dùng CPU nhiều nhất
ps aux --sort=-%cpu | head -10
# Top 10 process dùng RAM nhiều nhất
ps aux --sort=-%mem | head -10
# Process nào đang đọc/ghi disk nhiều nhất
iotop
Đừng vội kill process khi thấy nó ngốn tài nguyên. Đôi khi đó là process quan trọng (database, web server) đang xử lý tác vụ nặng. Hãy hiểu tại sao nó ngốn trước, rồi mới quyết định xử lý thế nào.
📖 Liên quan: Quản lý process – ps, kill, htop · Script Monitor VPS qua Telegram
Sự cố 4: Disk đầy
Sự cố này nghe đơn giản nhưng hậu quả thì không đơn giản chút nào. Khi disk đầy, database không ghi được, log không viết được, thậm chí bạn có thể không SSH được vì shell cần ghi file tạm.
Bước 1: Xác nhận disk thực sự đầy
df -hNhìn cột Use%. Nếu phân vùng / ở mức 100% (hoặc 99%), bạn cần giải phóng dung lượng ngay.
Bước 2: Tìm thư mục nào chiếm nhiều nhất
# Xem dung lượng từng thư mục cấp 1
du -sh /* 2>/dev/null | sort -rh | head -10
# Đào sâu vào thư mục nghi ngờ
du -sh /var/* 2>/dev/null | sort -rh | head -10
du -sh /var/log/* 2>/dev/null | sort -rh | head -10
Hoặc dùng ncdu nếu đã cài, công cụ này cho phép duyệt tương tác và rất trực quan:
ncdu /Xem thêm: Hướng dẫn sử dụng ncdu
Bước 3: Tìm file lớn
# Tìm file lớn hơn 100MB
find / -type f -size +100M 2>/dev/null | head -20
# Xem dung lượng cụ thể
find / -type f -size +100M -exec ls -lh {} \; 2>/dev/null | sort -k5 -rh | head -20
Bước 4: Dọn dẹp nhanh
Một số thủ phạm phổ biến và cách xử lý:
Log files phình to:
# Truncate log thay vì xóa (tránh lỗi với process đang ghi)
truncate -s 0 /var/log/syslog
truncate -s 0 /var/log/nginx/access.log
# Xóa log journal cũ
journalctl --vacuum-time=3d
journalctl --vacuum-size=100M
Package cache:
# Ubuntu/Debian
apt clean
apt autoremove
# CentOS/AlmaLinux/Rocky
dnf clean all
Docker images/containers cũ:
# Xem Docker dùng bao nhiêu dung lượng
docker system df
# Dọn sạch resources không dùng
docker system prune -a
Bước 5: Setup log rotation để tránh tái phát
Sau khi giải phóng dung lượng, cần đảm bảo log không phình lại. Kiểm tra logrotate đã được cấu hình chưa:
# Xem config logrotate
cat /etc/logrotate.conf
ls /etc/logrotate.d/
# Test logrotate chạy đúng không
logrotate -d /etc/logrotate.conf
Mẹo quan trọng: Dùng truncate -s 0 thay vì rm cho log file đang được process ghi vào. Nếu bạn rm file mà process vẫn giữ file descriptor, dung lượng sẽ không được giải phóng cho đến khi process đó kết thúc. Dùng lsof | grep deleted để kiểm tra có file nào đã bị xóa nhưng vẫn chiếm dung lượng không.
📖 Liên quan: Quản lý disk · ncdu · Kiểm tra inodes
Sự cố 5: Database không chạy
MySQL/MariaDB hoặc PostgreSQL bỗng dưng dừng, website báo lỗi “Error establishing a database connection”. Đây là sự cố mình gặp khá thường xuyên.
Bước 1: Kiểm tra trạng thái dịch vụ
# MySQL/MariaDB
systemctl status mysqld # CentOS/AlmaLinux/Rocky
systemctl status mysql # Ubuntu/Debian
systemctl status mariadb # Nếu dùng MariaDB
# PostgreSQL
systemctl status postgresql
Bước 2: Đọc error log
Error log là nơi đầu tiên bạn cần nhìn. Nó sẽ cho biết chính xác tại sao database dừng:
# MySQL/MariaDB error log
tail -50 /var/log/mysql/error.log # Ubuntu/Debian
tail -50 /var/log/mysqld.log # CentOS/AlmaLinux/Rocky
tail -50 /var/log/mariadb/mariadb.log # MariaDB trên CentOS
# PostgreSQL
tail -50 /var/log/postgresql/postgresql-*-main.log # Ubuntu/Debian
tail -50 /var/lib/pgsql/data/log/*.log # CentOS/AlmaLinux/Rocky
Bước 3: Các nguyên nhân phổ biến
Disk đầy: Database cần ghi data và log. Nếu disk full, nó sẽ dừng ngay. Kiểm tra df -h và giải phóng dung lượng như phần trên.
Hết RAM (bị OOM kill):
dmesg | grep -i "oom.*mysql\|oom.*mariadb\|oom.*postgres"
journalctl | grep -i "oom.*mysql\|oom.*mariadb\|oom.*postgres"Nếu database bị OOM Killer giết, bạn cần giảm bớt cấu hình bộ nhớ của nó. Ví dụ với MySQL/MariaDB, giảm innodb_buffer_pool_size trong config file.
Permission lỗi:
# Kiểm tra quyền thư mục data MySQL
ls -la /var/lib/mysql/
# Sửa quyền nếu sai
chown -R mysql:mysql /var/lib/mysql/
Port conflict: Nếu có process khác đang chiếm port 3306 (MySQL) hoặc 5432 (PostgreSQL):
ss -tlnp | grep 3306
ss -tlnp | grep 5432Sau khi xác định và fix nguyên nhân, khởi động lại database:
systemctl start mysqld # hoặc mysql, mariadb, postgresql
systemctl status mysqld # Verify nó đang chạy📖 Liên quan: Script tự khởi động MySQL · Backup/import database MySQL
Sự cố 6: VPS bị hack / bị đào coin
Đây là sự cố mà không ai muốn gặp, nhưng nếu bạn vận hành VPS đủ lâu thì sớm muộn cũng sẽ đối mặt. Kẻ tấn công thường lợi dụng VPS để đào cryptocurrency, gửi spam, hoặc làm bàn đạp tấn công server khác.
Dấu hiệu nhận biết
CPU luôn ở mức 100% với process lạ:
top -bn1 | head -20Nếu thấy process có tên lạ (dãy ký tự ngẫu nhiên, tên giả dạng như “kworker” nhưng ngốn CPU) chiếm 90-100% CPU, rất có thể VPS đang bị dùng để đào coin.
User lạ trong hệ thống:
# Kiểm tra user có shell login
grep -v "nologin\|false" /etc/passwd
# Kiểm tra user có quyền sudo
grep -v "^#" /etc/sudoers
ls -la /etc/sudoers.d/
Crontab lạ:
# Kiểm tra crontab của tất cả user
for user in $(cut -f1 -d: /etc/passwd); do
crontab_content=$(crontab -l -u "$user" 2>/dev/null)
if [ -n "$crontab_content" ]; then
echo "=== Crontab của $user ==="
echo "$crontab_content"
fi
done
# Kiểm tra cron directories
ls -la /etc/cron.d/
ls -la /etc/cron.daily/
File lạ trong hệ thống:
# Tìm file thực thi trong thư mục /tmp, /dev/shm (nơi malware hay ẩn)
find /tmp /dev/shm /var/tmp -type f -executable 2>/dev/null
# Tìm file được tạo/sửa gần đây
find / -mtime -1 -type f 2>/dev/null | grep -v "/proc\|/sys"
Quy trình xử lý
1. Isolate: Nếu VPS đang bị dùng để tấn công bên ngoài, hãy cô lập nó bằng cách block toàn bộ outbound traffic (trừ SSH của bạn):
# Block tất cả outbound, chỉ giữ SSH
iptables -P OUTPUT DROP
iptables -A OUTPUT -p tcp --dport 22 -j ACCEPT
iptables -A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT2. Kiểm tra và ghi nhận: Thu thập thông tin trước khi xóa bất cứ thứ gì. Bạn cần biết kẻ tấn công vào bằng cách nào để tránh bị lại:
# Xem lịch sử đăng nhập
last -20
lastb -20 # Đăng nhập thất bại
# Kiểm tra SSH authorized_keys bị thêm lén
find / -name "authorized_keys" 2>/dev/null -exec cat {} \;
# Xem kết nối mạng đang hoạt động
ss -tupn
3. Dọn dẹp: Kill process malware, xóa file lạ, xóa crontab lạ, xóa user lạ, xóa SSH key lạ.
4. Harden: Đổi tất cả mật khẩu, cập nhật hệ thống, kiểm tra lại cấu hình firewall, rà soát ứng dụng web có lỗ hổng không.
Thực tế phũ phàng: Nếu VPS đã bị compromise nghiêm trọng (đặc biệt là bị root), cách an toàn nhất là rebuild VPS mới từ đầu. Bạn không bao giờ chắc chắn 100% rằng đã dọn sạch hết. Backup data quan trọng, dựng server mới, restore data. Mất thời gian hơn nhưng an toàn hơn nhiều.
📖 Liên quan: Checklist bảo mật 15 bước · Bot cảnh báo SSH Telegram · Đọc log hệ thống
Bộ công cụ troubleshoot
Tóm tắt lại các công cụ đã dùng xuyên suốt bài, phân loại theo mục đích sử dụng để bạn dễ tra cứu:
System monitoring
| Công cụ | Mục đích | Cài đặt |
|---|---|---|
top |
Xem CPU, RAM, process realtime | Có sẵn |
htop |
Phiên bản trực quan hơn của top | apt/dnf install htop |
vmstat |
Thống kê tổng quan về hệ thống | Có sẵn |
iostat |
Thống kê Disk I/O | apt/dnf install sysstat |
sar |
Xem lịch sử performance (CPU, RAM, I/O) | apt/dnf install sysstat |
iotop |
Xem process nào đang đọc/ghi disk | apt/dnf install iotop |
Network
| Công cụ | Mục đích | Cài đặt |
|---|---|---|
ss |
Xem port đang listen, kết nối hiện tại | Có sẵn |
curl |
Test HTTP request | Có sẵn |
dig |
Kiểm tra DNS | apt install dnsutils / dnf install bind-utils |
traceroute |
Xem đường đi gói tin | apt/dnf install traceroute |
tcpdump |
Bắt và phân tích gói tin | apt/dnf install tcpdump |
iftop |
Xem bandwidth realtime | apt/dnf install iftop |
Log
| Công cụ | Mục đích |
|---|---|
journalctl |
Xem log của systemd services |
/var/log/ |
Thư mục chứa log hệ thống và ứng dụng |
dmesg |
Log kernel (phát hiện OOM, hardware errors) |
tail -f |
Theo dõi log realtime |
Disk
| Công cụ | Mục đích | Cài đặt |
|---|---|---|
df |
Xem dung lượng phân vùng | Có sẵn |
du |
Xem dung lượng thư mục/file | Có sẵn |
lsof |
Xem file đang mở bởi process nào | Có sẵn |
ncdu |
Xem dung lượng thư mục/tập tin qua giao diện | apt/dnf install ncdu |
Flowchart troubleshoot
Khi gặp sự cố, đây là quy trình ra quyết định bạn có thể theo:
VPS có sự cố
│
├─ SSH được không?
│ ├─ KHÔNG → Vào console provider → Kiểm tra: VPS running? sshd? firewall? fail2ban?
│ └─ ĐƯỢC → Tiếp tục ↓
│
├─ Website truy cập được không?
│ ├─ KHÔNG → DNS đúng? → Web server running? → Port listen? → Firewall? → SSL?
│ └─ ĐƯỢC nhưng chậm → Tiếp tục ↓
│
├─ VPS chậm/lag?
│ ├─ CPU cao → top/htop → Tìm process ngốn CPU
│ ├─ RAM hết → free -h → Process nào dùng nhiều? OOM?
│ ├─ Disk I/O cao → iostat → Process nào ghi nhiều?
│ └─ Network cao → iftop → DDoS? Process lạ?
│
├─ Disk đầy?
│ ├─ ĐÚNG → du -sh /* → Tìm thư mục/file lớn → Dọn dẹp → Setup logrotate
│ └─ KHÔNG → Tiếp tục ↓
│
├─ Database lỗi?
│ └─ Error log → Disk full? OOM? Permission? Port conflict? → Fix → Restart
│
└─ Nghi bị hack?
└─ CPU 100% process lạ? User lạ? Crontab lạ? → Isolate → Check → Clean → RebuildFlowchart này không bao quát mọi tình huống, nhưng sẽ giúp bạn có điểm bắt đầu rõ ràng thay vì loay hoay không biết kiểm tra gì trước.
Checkpoint: Tự tay thực hành
Lý thuyết đã đủ, giờ tự tay làm thử. Mình sẽ đưa ra một số bài tập giả lập sự cố để bạn luyện troubleshooting trên VPS thật (tất nhiên là VPS test, đừng chơi trên production).
Bài tập 1: Giả lập disk đầy
# Tạo file lớn giả lập disk đầy
fallocate -l 5G /tmp/fake-large-file
# Bây giờ thử troubleshoot:
# 1. Dùng df -h xác nhận disk usage tăng
# 2. Dùng du -sh /* tìm thư mục nào tăng
# 3. Dùng find tìm file lớn
# 4. Xóa file giả lập
rm /tmp/fake-large-file
Bài tập 2: Giả lập web server dừng
# Dừng nginx (hoặc apache)
systemctl stop nginx
# Thử troubleshoot:
# 1. curl localhost — xem lỗi gì
# 2. systemctl status nginx — xem trạng thái
# 3. ss -tlnp | grep 80 — port có listen không
# 4. Fix: systemctl start nginx
# 5. Verify: curl localhost
Bài tập 3: Giả lập process ngốn CPU
# Tạo process giả chiếm CPU
yes > /dev/null &
# Troubleshoot:
# 1. top — tìm process chiếm CPU
# 2. Ghi lại PID của process đó
# 3. ps aux | grep [PID]
# 4. Kill nó: kill [PID]
# 5. Verify bằng top lại
Bài tập 4: Giả lập SSH bị block
Cẩn thận với bài tập này! Chỉ làm khi bạn có sẵn quyền truy cập console qua panel provider. Nếu không, bạn sẽ bị khóa ngoài thật.
# Đổi port SSH sang port khác (qua console provider)
# Sửa /etc/ssh/sshd_config: Port 2222
systemctl restart sshd
# Thử SSH bằng port 22 — sẽ thất bại
# Troubleshoot:
# 1. ss -tlnp | grep ssh — xem sshd listen port nào
# 2. Phát hiện port 2222
# 3. SSH lại bằng port 2222: ssh -p 2222 user@ip
# 4. Sửa lại Port 22, restart sshdMỗi bài tập trên giả lập đúng một sự cố đã bàn trong bài. Mục tiêu không phải fix nhanh (vì bạn đã biết “bệnh”), mà là luyện tập quy trình: triệu chứng → thu thập data → giả thuyết → kiểm tra → fix → verify.
Kết bài
Troubleshooting không phải là biết hết mọi lỗi. Không ai biết hết. Cái quan trọng là có phương pháp tiếp cận đúng: bình tĩnh, thu thập data, đặt giả thuyết, kiểm tra từng cái một.
6 sự cố trong bài này chiếm phần lớn các tình huống bạn sẽ gặp khi vận hành VPS. Nắm vững cách xử lý chúng, kết hợp với bộ công cụ troubleshoot đã liệt kê, bạn sẽ tự tin hơn rất nhiều khi server “dở chứng” lúc nửa đêm.
Và nhớ: ghi chép lại mỗi sự cố bạn gặp và cách giải quyết. Tạo một file runbook riêng cho server của mình. Lần sau gặp lại, bạn sẽ cảm ơn chính mình đã ghi chép.
Có thể bạn cần xem thêm
- Systemd và quản lý service trên Linux VPS
- Checklist bảo mật VPS Linux - 15 bước thiết yếu
- Quản lý process trên Linux - ps, kill, htop cho VPS
- Tổng hợp lỗi hiệu năng VPS phổ biến và cách khắc phục từ A-Z
- Quản lý disk trên Linux VPS - kiểm tra dung lượng, mount, lsblk, fdisk và mở rộng ổ đĩa
- Logging, Monitoring và IDS trên Linux VPS - auditd, AIDE và Wazuh
Về tác giả

Thạch Phạm
Đồng sáng lập và Giám đốc điều hành của AZDIGI. Có hơn 15 năm kinh nghiệm trong phổ biến kiến thức liên quan đến WordPress tại thachpham.com, phát triển website và phát triển hệ thống.