
vLLM là một inference engine mã nguồn mở chuyên để phục vụ mô hình ngôn ngữ với thông lượng cao và độ trễ thấp. Nếu Ollama nổi tiếng vì cài nhanh, chạy gọn và hợp cho giai đoạn thử nghiệm, thì vLLM lại đi theo hướng khác: tối ưu cho API serving nghiêm túc, nhiều request đồng thời và mô hình lớn hơn.
Đó cũng là lý do rất nhiều team bắt đầu bằng Ollama rồi một lúc sau lại đi tìm “vLLM là gì” hoặc “vLLM vs Ollama”. Khi ứng dụng AI bắt đầu có người dùng thật, nhu cầu thường đổi rất nhanh: cần OpenAI compatible API, cần batch request tốt hơn, cần tận dụng GPU hiệu quả hơn, cần scale ra nhiều GPU hoặc cần chạy model lớn hơn.

Mục lục
- vLLM là gì
- vLLM hoạt động tốt ở điểm nào
- vLLM vs Ollama
- Khi nào nên dùng vLLM thay Ollama
- Khi nào vẫn nên chọn Ollama
- Hạ tầng phù hợp để chạy vLLM
- Câu hỏi thường gặp
vLLM là gì
vLLM là engine phục vụ LLM tập trung vào hiệu năng suy luận. Dự án này cung cấp HTTP server tương thích với OpenAI API, hỗ trợ serve model qua endpoint chat/completions và nhiều API khác. Nói theo cách thực dụng hơn, vLLM là lớp đứng giữa model và ứng dụng của bạn, lo chuyện nhận request, gom batch, dùng bộ nhớ GPU hiệu quả và trả kết quả ra ngoài dưới dạng API.
Tài liệu chính thức của vLLM nhấn mạnh hai điểm mà dân triển khai rất quan tâm: OpenAI-compatible server và hàng loạt tối ưu cho serving, trong đó nổi bật là PagedAttention, continuous batching, tensor parallelism và hỗ trợ quantization.
ℹ️ Hiểu nhanh thì Ollama thiên về “chạy model cho nhanh”, còn vLLM thiên về “biến model thành dịch vụ API tử tế”.
vLLM mạnh ở đâu
- PagedAttention: dùng bộ nhớ KV cache tiết kiệm hơn, đặc biệt khi context dài.
- Continuous batching: request đến liên tục vẫn có thể được gộp vào batch đang chạy, tăng hiệu suất GPU.
- Tensor parallelism: chia model qua nhiều GPU khi model lớn hơn khả năng của một GPU.
- Quantization: giảm dung lượng model và áp lực VRAM bằng INT4, INT8, FP8 tùy case.
- OpenAI compatible server: ứng dụng đã nói chuyện với OpenAI API thường đổi sang vLLM khá nhẹ.
Đây là lý do vLLM thường xuất hiện trong các bài toán chatbot nhiều người dùng, API nội bộ cho ứng dụng AI, hệ thống RAG có traffic thật hoặc các dịch vụ inference cần kiểm soát chi phí GPU.

vLLM vs Ollama: Khác nhau ở đâu
| Tiêu chí | Ollama | vLLM |
|---|---|---|
| Mục tiêu chính | Chạy model nhanh, dễ dùng | Serve model hiệu quả ở mức production |
| Đối tượng phù hợp | Dev cá nhân, lab nhỏ, prototyping | ML engineer, backend AI, team vận hành |
| Thông lượng | Vừa phải | Cao hơn khi có nhiều request đồng thời |
| Khả năng scale | Đơn giản, ít tuning | Tốt hơn cho multi-GPU và tuning hiệu năng |
| Tương thích API | API riêng của Ollama | OpenAI compatible API |
| Use case hợp nhất | Thử model, ứng dụng nội bộ nhẹ | API self-hosted, RAG traffic thật, app nhiều người dùng |
Bài Cài đặt Ollama trên VPS Ubuntu rất phù hợp nếu bạn mới bắt đầu. Còn khi đã có nhu cầu mở API cho ứng dụng web, bạn nên đọc thêm Ollama API để thấy giới hạn tự nhiên của stack đơn giản này trước khi nhảy sang vLLM.
Khi nào nên dùng vLLM thay Ollama
Đây là phần mà hầu hết mọi người quan tâm nhất. Theo kinh nghiệm triển khai thực tế, bạn nên nghiêng sang vLLM khi rơi vào một trong các tình huống sau.
- Ứng dụng đã có người dùng thật: nhiều request cùng lúc làm Ollama bắt đầu đuối.
- Bạn cần OpenAI compatible server: app đang dùng SDK OpenAI sẽ đổi endpoint dễ hơn nhiều.
- Bạn muốn tận dụng GPU tốt hơn: vLLM sinh ra để bóc hiệu năng inference chứ không chỉ chạy được.
- Bạn cần model lớn hoặc đa GPU: vLLM có lợi thế rõ hơn khi model không còn vừa một môi trường nhỏ.
- Bạn cần tối ưu chi phí suy luận: batching và quantization giúp kéo thêm hiệu suất trên cùng phần cứng.
⚠️ Nếu workload của bạn chỉ là một người dùng, vài prompt thử nghiệm mỗi ngày hoặc chatbot nội bộ cực nhẹ, chuyển sang vLLM quá sớm có khi lại làm hệ thống phức tạp lên mà chưa thu lại nhiều lợi ích.

Khi nào vẫn nên chọn Ollama
Ollama vẫn là lựa chọn rất ổn nếu mục tiêu của bạn là gọn, nhanh, ít vận hành. Cụ thể, hãy ở lại với Ollama nếu:
- Bạn đang thử prompt, test model hoặc làm demo nội bộ.
- Bạn muốn cài nhanh trên một VPS CPU hoặc máy cá nhân.
- Bạn chưa có nhu cầu batching, scale nhiều request hay tuning sâu.
- Bạn muốn kết hợp nhanh với Open WebUI, n8n hoặc app nhỏ.
Nói thẳng là vậy: Ollama thắng ở trải nghiệm bắt đầu, vLLM thắng khi bạn bắt đầu quan tâm nghiêm túc đến serving.
Chạy vLLM trên VPS có hợp không
Có, nhưng phải nhìn đúng kỳ vọng. Nếu bạn chỉ muốn thử OpenAI compatible server, test routing hoặc phục vụ model nhỏ, có thể bắt đầu bằng X-Platinum VPS hoặc AMD Cloud Server để dựng lớp API và quy trình vận hành. Còn nếu mục tiêu là phát huy hết lợi thế của vLLM, đặc biệt với model lớn và concurrency cao, môi trường có GPU mới là nơi vLLM thể hiện rõ nhất.
Trên AZDIGI, hướng đi an toàn là bắt đầu bằng VPS hoặc cloud server để dựng stack self-hosted, reverse proxy, auth, logging, rồi tách lớp inference chuyên biệt khi tải tăng lên. Bạn nên đọc thêm bài bảo mật AI self-hosted và reverse proxy cho Ollama vì các nguyên tắc vận hành API AI gần như giữ nguyên khi chuyển sang vLLM.
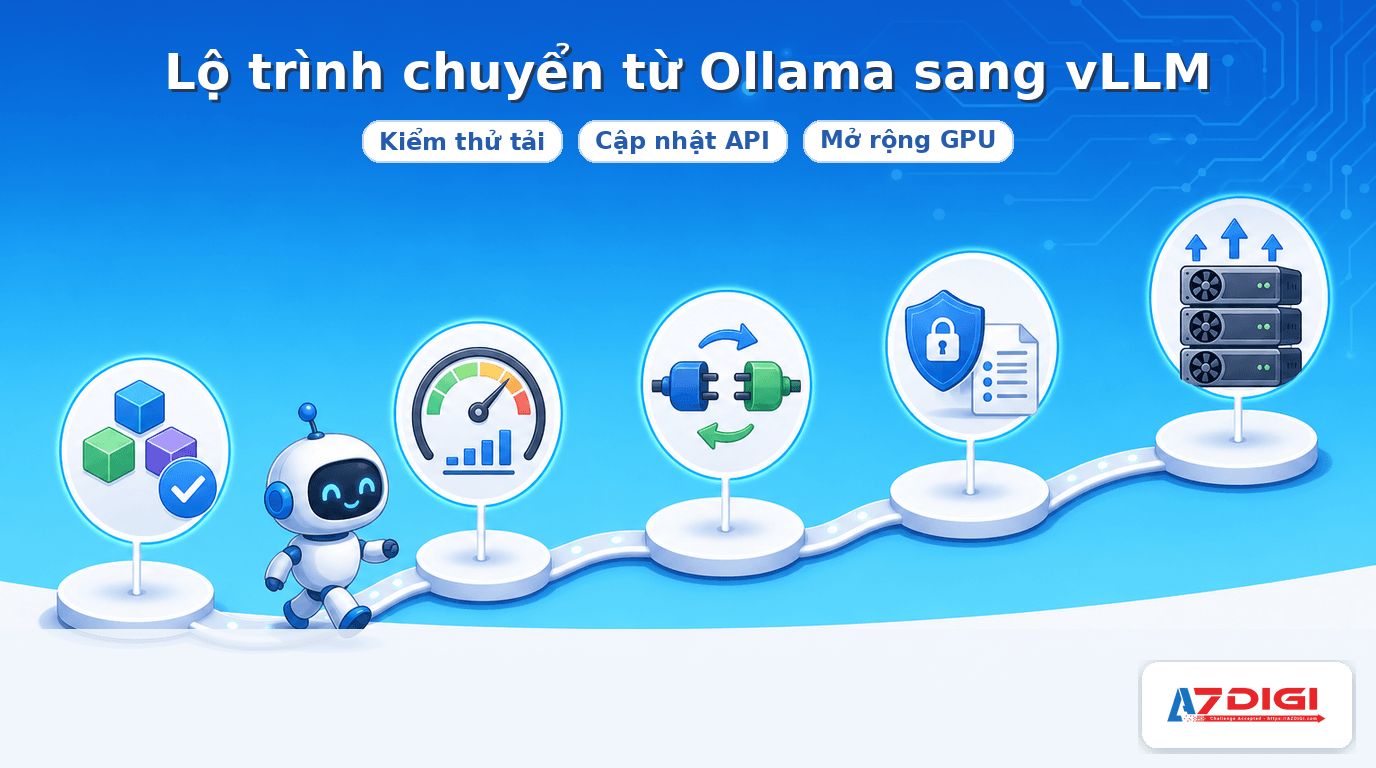
Một lộ trình chuyển từ Ollama sang vLLM khá an toàn
- Chốt model và prompt bằng Ollama trước.
- Đo nhu cầu thật: số người dùng, số request, độ dài context, token output.
- Chuyển lớp serving sang vLLM để lấy OpenAI compatible API.
- Thêm reverse proxy, auth, monitoring và giới hạn tần suất.
- Nếu model lớn hoặc traffic tăng mạnh, mới tính chuyện GPU và multi-GPU.
Cách đi này đỡ tốn tiền hơn kiểu thấy vLLM hay là nhảy vào ngay từ ngày đầu. Hầu hết dự án AI chết không phải vì thiếu engine xịn, mà vì chưa đo được workload thật.
Câu hỏi thường gặp về vLLM
vLLM có thay thế hoàn toàn Ollama không
Không hẳn. Hai công cụ giải quyết hai giai đoạn khác nhau. Ollama rất hợp để bắt đầu nhanh. vLLM hợp hơn khi bạn cần API serving nghiêm túc.
vLLM có chạy CPU được không
Có thể có một số mức hỗ trợ tùy môi trường, nhưng lợi thế lớn nhất của vLLM thường bộc lộ khi có GPU. Nếu chỉ chạy CPU cho nhu cầu nhẹ, Ollama thường dễ bắt đầu hơn.
OpenAI compatible server của vLLM có ích gì
Nó giúp app đang dùng SDK hoặc định dạng request kiểu OpenAI chuyển sang self-hosted dễ hơn. Đây là một trong những lý do khiến vLLM được chọn nhiều ở giai đoạn production.
Kết lại
Nếu bạn đang tìm câu trả lời ngắn cho “vLLM là gì”, thì đây là inference engine tối ưu cho việc phục vụ model qua API. Còn với câu hỏi “khi nào nên dùng vLLM thay Ollama”, câu trả lời hợp lý nhất là: khi bạn đã vượt qua giai đoạn thử nghiệm và bắt đầu cần hiệu năng, concurrency, khả năng scale và cách tích hợp gần chuẩn OpenAI hơn.
Nếu đang ở giai đoạn đầu, cứ dùng Ollama cho nhanh. Nếu đã bước vào giai đoạn phục vụ model cho ứng dụng thật, vLLM là cái tên rất đáng thử. Và nếu bạn muốn tự host toàn bộ stack trên AZDIGI, có thể bắt đầu từ VPS hoặc cloud server trước, rồi nâng dần lớp inference khi tải đủ lớn.
Có thể bạn cần xem thêm
- vLLM là gì? Khi nào nên dùng vLLM thay Ollama
- MCP là gì? Cách AI Agent kết nối tool và dữ liệu bên ngoài
- Flowise là gì? Khi nào nên self-hosted trên VPS để tạo chatbot AI
- Ollama API - Tích hợp AI self-hosted vào ứng dụng web
- CrewAI là gì? Hướng dẫn xây dựng hệ thống Multi-Agent AI với Python
- Kết nối OpenClaw với nhiều AI cùng lúc: Claude, ChatGPT, Gemini
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.