
Google DeepMind vừa phát hành Gemma 4 vào ngày 2/4/2026. Đây là thế hệ mới nhất trong dòng model AI mở của Google, xây dựng trên cùng công nghệ với Gemini 3. Có 4 phiên bản từ 2B đến 31B parameters, chạy được từ điện thoại đến server, và lần đầu tiên dùng license Apache 2.0.
Với hơn 400 triệu lượt download tổng cộng từ cộng đồng Gemma và hơn 100.000 model variants, đây là dòng model mở phổ biến nhất của Google hiện tại. Gemma 4 tiếp tục đà đó với hiệu năng vượt trội so với Gemma 3, cạnh tranh trực tiếp với Qwen 3.5 và Llama 4 ở cùng phân khúc.
Tổng quan Gemma 4
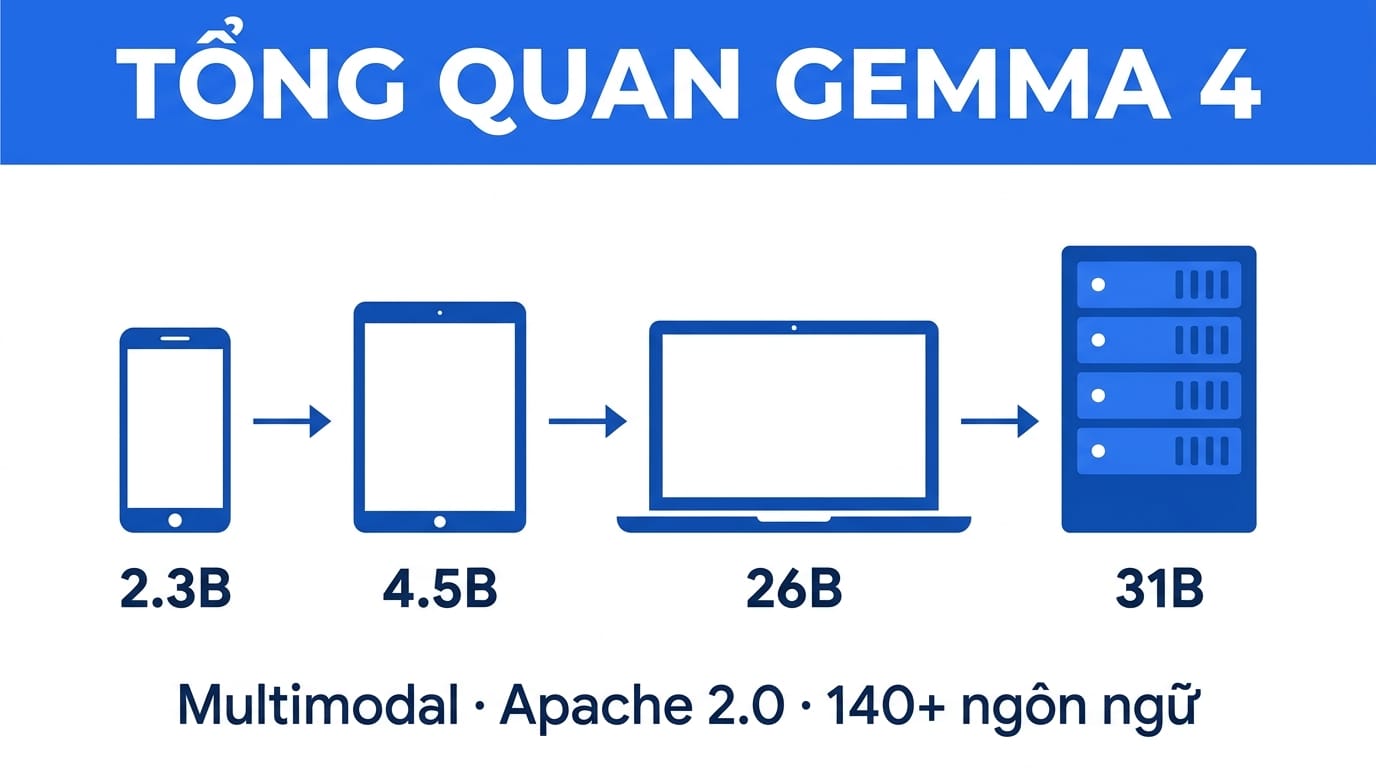
Gemma 4 có 4 model sizes, phục vụ từ edge/mobile cho đến workstation. Tất cả đều hỗ trợ multimodal (text, image), một số model nhỏ còn xử lý được audio và video.
Điểm khác biệt lớn nhất so với Gemma 3: license chuyển sang Apache 2.0. Các phiên bản Gemma trước dùng custom license với một số hạn chế thương mại. Giờ bạn có thể dùng cho mục đích gì cũng được, kể cả sản phẩm thương mại, mà không lo vấn đề bản quyền.
Về công nghệ, Gemma 4 được xây dựng từ cùng kiến trúc với Gemini 3. Sundar Pichai mô tả là “packing incredible amount of intelligence per parameter”, còn Demis Hassabis gọi đây là “best open models in the world for their respective sizes”.
Bốn phiên bản Gemma 4
Bảng dưới đây tóm tắt thông số chính của 4 model:
| Model | Parameters | Active params | Context | Modalities |
|---|---|---|---|---|
| E2B | 5.1B (effective 2.3B) | 2.3B | 128K | Text, Image, Audio |
| E4B | 8B (effective 4.5B) | 4.5B | 128K | Text, Image, Audio, Video |
| 26B MoE (A4B) | 25.2B | 3.8B | 256K | Text, Image |
| 31B Dense | 30.7B | 30.7B | 256K | Text, Image |
E2B và E4B: nhỏ gọn, chạy offline
E2B (Effective 2B) có 5.1B parameters tổng nhưng chỉ 2.3B effective. Chạy được trên điện thoại, Raspberry Pi, Jetson Nano. Hỗ trợ text, image và audio (nhờ USM-style conformer encoder). Với 128K context window, model này phù hợp cho các ứng dụng offline, embedded AI.
E4B (Effective 4B) lớn hơn một chút: 8B total, 4.5B effective. Cũng chạy được trên thiết bị nhỏ. Cái hay là E4B xử lý được cả video (tối đa 60 giây ở 1fps), ngoài text, image và audio.
26B MoE (A4B): hiệu suất cao, tài nguyên thấp
Đây là model Mixture-of-Experts với 25.2B parameters tổng, nhưng mỗi inference chỉ dùng 3.8B active parameters. Kiến trúc gồm 128 experts, mỗi lần chọn 8 expert cộng 1 shared expert.
Context window 256K tokens. Hiểu nôm na: bạn có model 25B nhưng tốc độ inference gần bằng model 4B. Trên MacBook M4 với 38GB RAM, model này chạy khoảng 42-43 tokens/second. Trên M2 Ultra với llama.cpp đạt tới 300 t/s.
31B Dense: mạnh nhất dòng Gemma
Model 30.7B dense, không dùng MoE nên mọi parameter đều active. Hiện đứng #3 trên Arena AI cho open models (tính đến 2/4/2026). Context window 256K tokens, hỗ trợ text và image.
Để chạy 31B unquantized cần 1x 80GB H100. Nhưng nếu quantize xuống thì chạy được trên consumer GPU bình thường.
Điểm mạnh và khả năng nổi bật
Reasoning và thinking mode
Gemma 4 hỗ trợ chain-of-thought reasoning qua token <|think|>. Khi bật thinking mode, model sẽ “suy nghĩ” trước khi trả lời, giúp cải thiện đáng kể kết quả ở các bài toán phức tạp. Ví dụ ở benchmark AIME 2026, Gemma 4 31B đạt 89.2% trong khi Gemma 3 27B chỉ được 20.8%.
Agentic workflows
Gemma 4 có native function-calling, structured JSON output, và system instructions. Nghĩa là bạn có thể dùng model làm AI agent: gọi API, trích xuất dữ liệu có cấu trúc, xử lý multi-step tasks mà không cần framework phức tạp bên ngoài.
Multimodal: vision, audio, video
Tất cả 4 model đều xử lý được image. Khả năng vision bao gồm OCR, đọc biểu đồ, phát hiện vật thể với JSON bounding boxes, và variable image token budgets (70 đến 1120 tokens tùy độ phức tạp ảnh).
E2B và E4B có thêm audio encoder (USM-style conformer), hỗ trợ nhận dạng giọng nói (ASR), tối đa 30 giây mỗi clip. E4B còn xử lý được video, tối đa 60 giây ở 1fps.
Code generation
Gemma 4 31B đạt 2150 Codeforces ELO và 80% trên LiveCodeBench. Con số này cho thấy model viết code khá tốt, có thể dùng làm offline code assistant. Ngay cả model nhỏ nhất E2B cũng đạt 633 ELO trên Codeforces, đủ dùng cho các tác vụ code cơ bản.
140+ ngôn ngữ
Vocabulary của Gemma 4 lên tới 262K tokens, lớn hơn nhiều so với mức 32K-150K thông thường ở các model khác. Điều này giúp model xử lý tốt hơn 140 ngôn ngữ native, bao gồm tiếng Việt.
Benchmark: Gemma 4 mạnh cỡ nào?
Dưới đây là bảng benchmark so sánh giữa các phiên bản Gemma 4 và Gemma 3 27B (nguồn: Google Gemma 4 Model Card):
| Model | MMLU-Pro | GPQA Diamond | LiveCodeBench | Codeforces ELO | MMMLU |
|---|---|---|---|---|---|
| Gemma 4 31B | 85.2% | 84.3% | 80.0% | 2150 | 88.4% |
| Gemma 4 26B A4B | 82.6% | 82.3% | 77.1% | 1718 | 86.3% |
| Gemma 4 E4B | 69.4% | 58.6% | 52.0% | 940 | 76.6% |
| Gemma 4 E2B | 60.0% | 43.4% | 44.0% | 633 | 67.4% |
| Gemma 3 27B | 67.6% | 42.4% | 29.1% | 110 | 70.7% |
Nhìn vào bảng, Gemma 4 31B mạnh hơn Gemma 3 27B ở mọi chỉ số. Chênh lệch lớn nhất là ở code (Codeforces ELO 2150 vs 110) và reasoning (GPQA Diamond 84.3% vs 42.4%). Bước nhảy này một phần nhờ thinking mode mới. Số liệu AIME 2026 (89.2% vs 20.8%) cũng từ model card chính thức.
Đáng chú ý là 26B MoE (A4B) cũng rất mạnh dù chỉ dùng 3.8B active params mỗi inference. GPQA Diamond đạt 82.3%, gần bằng bản 31B Dense. Đây là lựa chọn tốt nếu bạn muốn cân bằng giữa hiệu năng và tài nguyên.
So sánh với các đối thủ cùng phân khúc
So với Qwen 3.5 27B (theo Artificial Analysis): Qwen nhỉnh hơn nhẹ ở reasoning (GPQA Diamond 85.8% vs 85.7% ở reasoning mode). Qwen cũng có context window lớn hơn (trên 1M tokens). Nhưng Gemma 4 thắng ở multimodal (audio + vision tích hợp sẵn) và license Apache 2.0 thoáng hơn.
So với DeepSeek: DeepSeek 671B vẫn mạnh hơn, nhưng cần hardware lớn hơn rất nhiều. Gemma 4 31B cho kết quả “genuinely close” ở nhiều tác vụ mà chỉ cần một phần nhỏ tài nguyên.
So với Llama 4 Scout: Llama có context window tới 10M tokens, nhưng 256K của Gemma 4 đã đủ cho phần lớn use cases thực tế. Gemma 4 hiện dominate phân khúc giá rẻ/edge trên LMArena.
Nguồn benchmark: bảng chính từ Google Gemma 4 Model Card. So sánh cross-model từ Artificial Analysis (independent testing). Ranking Arena AI từ arena.ai tính đến ngày 2/4/2026. Thông tin chi tiết về Gemma 4 từ blog chính thức Google.
Kiến trúc kỹ thuật
Gemma 4 có một số thay đổi kiến trúc đáng chú ý so với các transformer thông thường. Dưới đây là các điểm chính, giải thích ngắn gọn cho dễ hình dung.
Hybrid Attention
Thay vì dùng toàn bộ global attention (tốn memory, chậm với context dài), Gemma 4 xen kẽ giữa sliding-window attention (chỉ nhìn 512 hoặc 1024 tokens gần nhất) và global full-context attention. Layer cuối cùng luôn là global để model vẫn “nhìn thấy” toàn bộ context khi cần.
Cách làm này tiết kiệm bộ nhớ đáng kể mà vẫn giữ được khả năng xử lý context dài.
Per-Layer Embeddings (PLE)
Ở các model thông thường, tất cả layers dùng chung một embedding vector đầu vào. Gemma 4 cho mỗi layer một vector conditioning riêng. Nôm na là mỗi layer nhận thêm một “tín hiệu” riêng để biết mình ở đâu trong mạng và nên xử lý gì. Kỹ thuật này giúp model học hiệu quả hơn với cùng số parameters.
Shared KV Cache
Các layer cuối của model reuse Key/Value cache từ layer trước thay vì tự tính toán riêng. Hiểu đơn giản: thay vì mỗi layer tốn bộ nhớ riêng cho KV cache, một số layer “mượn” cache của layer trước. Kết quả: giảm memory và compute mà chất lượng output gần như không đổi.
Dual RoPE và GQA
Gemma 4 dùng hai base frequency khác nhau cho RoPE (Rotary Position Embedding): sliding layers dùng base 10K, global layers dùng base 1M. Base lớn hơn giúp global layers encode vị trí chính xác hơn khi context dài.
Grouped Query Attention (GQA) cũng được cấu hình khác nhau giữa local và global: local dùng 2 queries trên 1 KV head, global dùng 8 queries trên 1 KV head. Cách này nén memory hiệu quả, đặc biệt ở các layer global phải xử lý toàn bộ context.
Cách chạy Gemma 4 trên máy cá nhân

Gemma 4 được hỗ trợ ngay từ ngày ra mắt trên hầu hết các công cụ phổ biến. Dưới đây là một số cách chạy nhanh nhất.
Ollama
Cách đơn giản nhất là pull model trước, sau đó chạy trực tiếp bằng lệnh ollama run:
# Tải model mặc định
ollama pull gemma4
# Chạy model sau khi pull xong
ollama run gemma4Với Ollama, bạn có thể pull và run theo đúng tag của từng phiên bản nếu muốn kiểm soát model cụ thể:
# Bản 31B Dense
ollama pull gemma4:31b
ollama run gemma4:31b
# Bản nhỏ
ollama pull gemma4:e2b
ollama run gemma4:e2b
ollama pull gemma4:e4b
ollama run gemma4:e4bNếu muốn kiểm tra model đã tải về chưa, bạn có thể dùng thêm lệnh ollama list. Trường hợp chạy qua API local thay vì giao diện dòng lệnh, chỉ cần pull model trước rồi gọi tới Ollama server là được.
llama.cpp
Hỗ trợ day-0, hiệu năng tốt. Tải model GGUF từ Hugging Face rồi chạy:
./llama-server -m gemma-4-26b-a4b-Q4_K_M.gguf -c 8192 -ngl 99Trên M2 Ultra, 26B MoE đạt khoảng 300 tokens/second. Trên M4 với 38GB RAM thì khoảng 42-43 t/s.
MLX (Apple Silicon)
Nếu bạn dùng Mac với Apple Silicon, MLX là lựa chọn tốt với TurboQuant support:
pip install mlx-lm
mlx_lm.generate --model google/gemma-4-26b-a4b-mlx --prompt "Hello"Các nền tảng khác
Gemma 4 cũng có sẵn trên Hugging Face, Kaggle, Google AI Studio, và NVIDIA NIM. Bạn có thể dùng trực tiếp qua API hoặc tải về chạy local tùy nhu cầu.
💡 Nếu máy bạn có dưới 16GB RAM, nên bắt đầu với E2B hoặc E4B. Từ 32GB trở lên thì 26B MoE chạy khá mượt.
Gemma 4 trên mobile và thiết bị edge
Google thiết kế E2B và E4B đặc biệt cho edge/mobile. Hai model này chạy được trên phone, Raspberry Pi, Jetson Nano, hoàn toàn offline. So với phiên bản trước, Google công bố nhanh hơn 4x và tiết kiệm 60% pin.
Gemma 4 cũng là nền tảng cho Gemini Nano 4 sắp ra mắt trên thiết bị Google Pixel. Google đang hợp tác với Qualcomm và MediaTek để tối ưu cho chip mobile. Android developers có thể truy cập qua AICore Developer Preview.
ℹ️ E2B và E4B có thể chạy hoàn toàn offline, không cần kết nối internet. Phù hợp cho các ứng dụng cần bảo mật dữ liệu hoặc vùng không có mạng.
Nên chọn Gemma 4 khi nào?
Gemma 4 phù hợp trong một số tình huống cụ thể:
- Cần chạy AI local/offline: E2B, E4B chạy trên thiết bị nhỏ, 26B MoE chạy trên laptop/workstation với tốc độ tốt.
- License quan trọng: Apache 2.0 cho phép dùng thương mại thoải mái, không hạn chế như một số model khác.
- Cần multimodal: Vision, audio, video tích hợp sẵn. Không cần ghép thêm model ngoài.
- Agentic AI: Function-calling, JSON output, system instructions hỗ trợ native.
- Edge/mobile deployment: Tối ưu cho phone, IoT, Raspberry Pi.
- Đa ngôn ngữ: 140+ ngôn ngữ, vocabulary 262K tokens.
Nếu bạn cần context window cực dài (trên 256K), Qwen 3.5 hoặc Llama 4 Scout có thể phù hợp hơn. Nếu cần hiệu năng tuyệt đối bất kể hardware, DeepSeek 671B vẫn là lựa chọn hàng đầu.
Câu hỏi thường gặp
Gemma 4 khác gì Gemini?
Gemma 4 là dòng model mở (open-weight) của Google, dùng cùng công nghệ với Gemini 3 nhưng kích thước nhỏ hơn. Gemini là model closed-source chạy trên cloud, còn Gemma bạn có thể tải về chạy local.
Máy cần cấu hình tối thiểu bao nhiêu để chạy Gemma 4?
E2B chạy được trên Raspberry Pi, phone. E4B tương tự. 26B MoE cần khoảng 16-32GB RAM (quantized). 31B Dense unquantized cần GPU 80GB, nhưng quantized thì chạy được trên consumer GPU 24GB.
Gemma 4 có miễn phí không?
Có. License Apache 2.0, miễn phí cho cả mục đích cá nhân lẫn thương mại. Tải về từ Hugging Face, Kaggle, hoặc Ollama.
Nên chọn 26B MoE hay 31B Dense?
Nếu ưu tiên tốc độ và tiết kiệm tài nguyên, chọn 26B MoE. Chỉ 3.8B active params nên rất nhanh. Nếu cần hiệu năng cao nhất có thể và hardware đủ mạnh, chọn 31B Dense.
Gemma 4 có hỗ trợ tiếng Việt không?
Có. Gemma 4 hỗ trợ hơn 140 ngôn ngữ, bao gồm tiếng Việt. Vocabulary 262K tokens cũng giúp tokenize tiếng Việt hiệu quả hơn so với các model có vocabulary nhỏ.
Gemma 4 so với Gemma 3 cải thiện bao nhiêu?
Cải thiện rất lớn. Ví dụ: AIME 2026 từ 20.8% lên 89.2%, GPQA Diamond từ 42.4% lên 84.3%, Codeforces ELO từ 110 lên 2150. Đây là bước nhảy đáng kể, nhờ kiến trúc mới và thinking mode.
Dùng Gemma 4 làm code assistant được không?
Được. Gemma 4 31B đạt 80% trên LiveCodeBench và 2150 Codeforces ELO. Ngay cả 26B MoE cũng đạt 77.1% LiveCodeBench. Bạn có thể dùng làm offline code assistant qua Ollama hoặc llama.cpp, kết hợp với editor như VS Code thông qua extension tương thích.
Có thể bạn cần xem thêm
- Cài đặt Ollama trên VPS Ubuntu - Chạy AI riêng trong 15 phút
- Generative AI: công nghệ đứng sau ChatGPT, Gemini và làn sóng AI tạo sinh
- Neural Network là gì? Cách mạng nơ-ron nhân tạo "học" từ dữ liệu
- Chạy DeepSeek trên VPS không cần GPU - Hướng dẫn chi tiết với Ollama
- Chọn model AI phù hợp VPS - Llama vs Qwen vs DeepSeek vs Gemma
- Deep Learning và Machine Learning khác nhau chỗ nào? (giải thích dễ hiểu)
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.