
Ollama là công cụ cho phép bạn chạy các mô hình AI (LLM) ngay trên server của mình. Thay vì phụ thuộc vào ChatGPT hay Claude rồi trả phí theo token, bạn có thể tự host một con AI riêng, dữ liệu không đi đâu cả, muốn hỏi bao nhiêu thì hỏi.
Mình vừa test thử trên một con VPS Ubuntu 4 vCPU, 3.8GB RAM, không có GPU gì hết. Kết quả: chạy được, tốc độ chấp nhận được, và cài đặt thì chỉ mất đúng 1 lệnh. Bài này mình sẽ đi từ đầu đến cuối, bạn theo là chạy được.
Yêu cầu VPS tối thiểu
Ollama chạy được trên CPU, không bắt buộc phải có GPU. Tất nhiên có GPU thì nhanh hơn nhiều, nhưng nếu bạn chỉ dùng model nhỏ (3B, 7B) thì CPU vẫn ổn.
| Thông số | Tối thiểu | Khuyến nghị |
|---|---|---|
| CPU | 2 vCPU | 4 vCPU trở lên |
| RAM | 4 GB | 8 GB trở lên |
| Disk | 20 GB trống | 40 GB trở lên |
| OS | Ubuntu 22.04 / 24.04 | Ubuntu 24.04 |
| GPU | Không bắt buộc | NVIDIA (nếu có) |
Trong bài này mình dùng VPS 4 vCPU, 3.8GB RAM, Ubuntu 24.04, chạy CPU-only. Đủ để chạy model 3B thoải mái.
Cài đặt Ollama
Đúng 1 lệnh, không cần thêm gì:
curl -fsSL https://ollama.com/install.sh | sh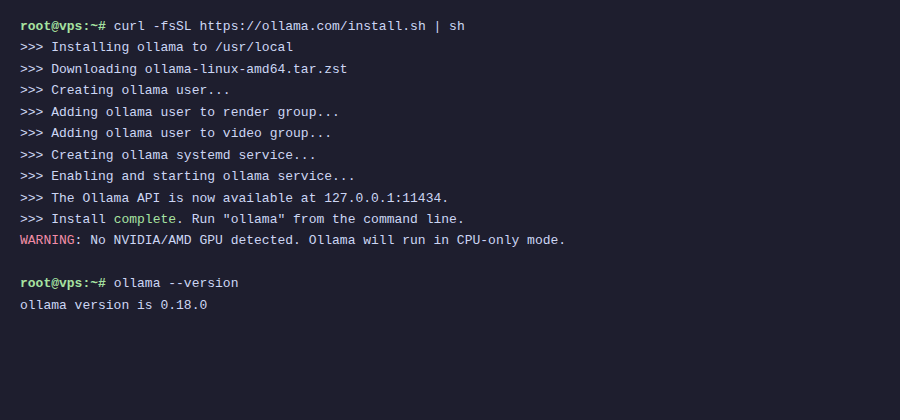
Script này sẽ tự detect hệ điều hành, tải binary, tạo user ollama, và setup systemd service luôn. Sau khi chạy xong bạn sẽ thấy dòng thông báo cài thành công.
Nếu VPS không có GPU, bạn sẽ thấy dòng WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode. Không sao cả, vẫn chạy bình thường.
Kiểm tra version:
ollama --versionMình cài được version 0.18.0. Ollama update khá thường xuyên nên version của bạn có thể mới hơn.
Ollama chạy như một service nền, start tự động khi boot. Bạn có thể kiểm tra trạng thái bằng:
sudo systemctl status ollamaPull model đầu tiên
Ollama cài xong thì chưa có model nào cả. Bạn cần pull về trước khi dùng.
Mình chọn Qwen 2.5 3B làm model đầu tiên vì mấy lý do:
- Nhẹ, chỉ 1.9GB, phù hợp VPS RAM thấp
- Hỗ trợ tiếng Việt khá tốt (tốt hơn Llama 3 cùng size)
- Của Alibaba Cloud, train trên dữ liệu đa ngôn ngữ nên hiểu context tiếng Việt ổn
- 3B parameter chạy CPU vẫn ra tốc độ dùng được
Pull model về:
ollama pull qwen2.5:3b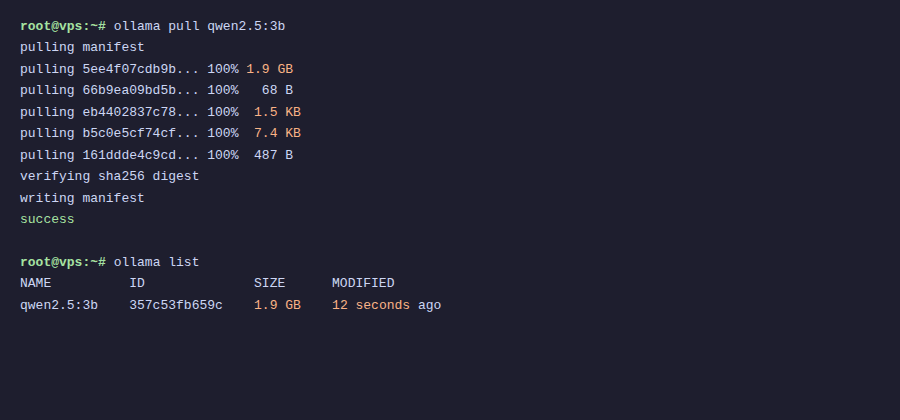
Tải về khoảng 1.9GB, tùy tốc độ mạng của VPS mà nhanh hay chậm. VPS AZDIGI thì thường vài phút là xong.
Chat thử trong terminal
Cách nhanh nhất để test là dùng lệnh ollama run:
ollama run qwen2.5:3bGõ xong sẽ vào chế độ chat interactive. Thử hỏi tiếng Việt:
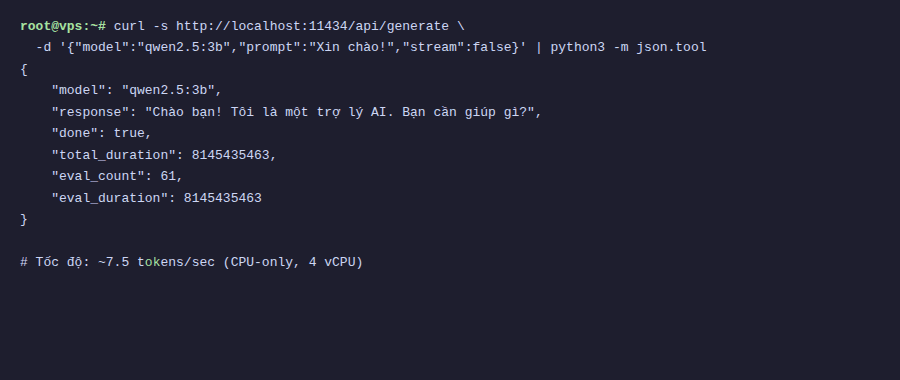
Trên con VPS test của mình, tốc độ trả lời khoảng 7.5 tokens/giây với tiếng Việt và 9.3 tokens/giây với tiếng Anh. Không nhanh bằng ChatGPT, nhưng hoàn toàn dùng được. Đọc kịp thì nó generate kịp.
Để thoát khỏi chế độ chat, gõ /bye hoặc nhấn Ctrl+D.
Sử dụng Ollama API
Ollama mặc định chạy API server tại http://localhost:11434. Bạn có thể gọi API bằng curl hoặc tích hợp vào ứng dụng của mình.
Kiểm tra Ollama đang chạy:
curl http://localhost:11434Nếu trả về Ollama is running là OK.
Gửi prompt qua API:
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:3b",
"prompt": "Docker là gì? Giải thích ngắn gọn.",
"stream": false
}'Response trả về dạng JSON, trong đó field response chứa câu trả lời. Tham số "stream": false để nhận toàn bộ response một lần thay vì stream từng token.
Chat API (có lịch sử hội thoại):
curl http://localhost:11434/api/chat -d '{
"model": "qwen2.5:3b",
"messages": [
{"role": "user", "content": "Xin chào, bạn là ai?"}
],
"stream": false
}'Chat API khác generate ở chỗ nó nhận mảng messages, bạn có thể truyền cả lịch sử hội thoại vào để model có context.
Xem danh sách model qua API:
curl http://localhost:11434/api/tagsCấu hình nâng cao
Mặc định Ollama chỉ listen trên localhost, tức là chỉ truy cập được từ chính VPS đó. Nếu bạn muốn cho ứng dụng từ máy khác gọi API, cần thay đổi bind address.
Mở file service của Ollama:
sudo systemctl edit ollamaThêm nội dung sau:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"Sau đó restart Ollama:
sudo systemctl daemon-reload
sudo systemctl restart ollamaKhi bind ra 0.0.0.0, API sẽ mở cho mọi IP truy cập. Nếu VPS có IP public, nhớ cấu hình firewall để chặn port 11434 từ bên ngoài, hoặc dùng reverse proxy (Nginx/Caddy) có authentication phía trước.
Một số biến môi trường hữu ích khác:
| Biến môi trường | Mô tả | Mặc định |
|---|---|---|
OLLAMA_HOST | Địa chỉ bind | 127.0.0.1:11434 |
OLLAMA_MODELS | Thư mục lưu model | ~/.ollama/models |
OLLAMA_NUM_PARALLEL | Số request xử lý song song | 1 |
OLLAMA_MAX_LOADED_MODELS | Số model load cùng lúc | 1 |
Quản lý model
Sau khi dùng một thời gian, bạn sẽ cần quản lý các model đã tải. Đây là các lệnh hay dùng:
Xem danh sách model đã tải:
ollama list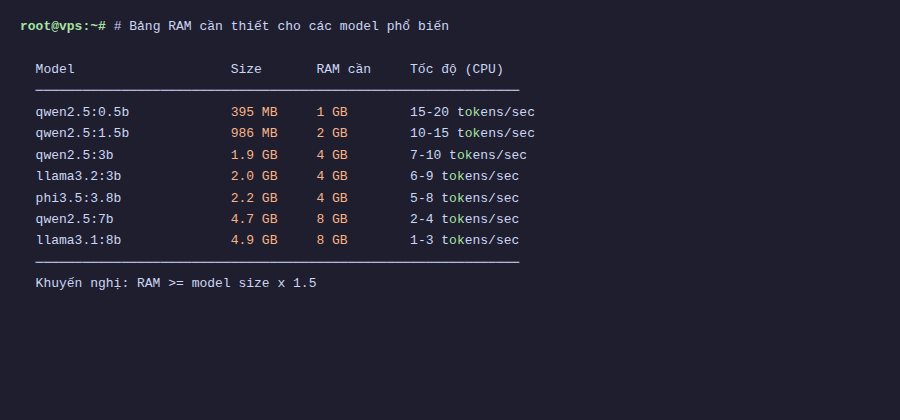
Tải thêm model mới:
ollama pull llama3.2:3b
ollama pull gemma3:4bXóa model không dùng nữa:
ollama rm qwen2.5:3bXem thông tin chi tiết của model:
ollama show qwen2.5:3bLệnh show sẽ hiển thị thông tin như architecture, parameter count, quantization, context length của model.
RAM cần bao nhiêu?
Đây là câu hỏi mình hay nhận được. Cơ bản thì model càng lớn (nhiều parameter) thì cần càng nhiều RAM. Dưới đây là bảng tham khảo:
| Model | Parameters | Dung lượng | RAM tối thiểu |
|---|---|---|---|
| Qwen 2.5 3B | 3B | 1.9 GB | 4 GB |
| Llama 3.2 3B | 3B | 2.0 GB | 4 GB |
| Gemma 3 4B | 4B | 3.0 GB | 6 GB |
| Qwen 2.5 7B | 7B | 4.7 GB | 8 GB |
| Llama 3.1 8B | 8B | 4.9 GB | 8 GB |
| Qwen 2.5 14B | 14B | 9.0 GB | 16 GB |
| Llama 3.3 70B | 70B | 43 GB | 64 GB |
Quy tắc nhanh: RAM cần ít nhất gấp đôi dung lượng file model. Ví dụ model 1.9GB thì nên có tối thiểu 4GB RAM. Ngoài ra hệ điều hành cũng cần RAM riêng, nên để dư thêm 1-2GB.
Với VPS 4GB RAM, bạn chạy thoải mái các model 3B. Muốn chạy model 7-8B thì nên có ít nhất 8GB. Còn model 70B thì cần server riêng rồi, VPS thông thường không đủ.
Tổng kết
Vậy là bạn đã có một con AI chạy riêng trên VPS rồi. Tổng thời gian từ lúc bắt đầu đến lúc chat được chắc chưa tới 15 phút (phần lớn là chờ tải model).
Tóm lại những gì đã làm:
- Cài Ollama bằng 1 lệnh duy nhất
- Pull model Qwen 2.5 3B (1.9GB, hỗ trợ tiếng Việt)
- Chat trực tiếp trong terminal
- Gọi API để tích hợp vào ứng dụng
- Cấu hình bind address và biến môi trường
- Quản lý model (pull, list, rm, show)
Chat trong terminal thì cũng vui, nhưng dùng lâu sẽ thấy thiếu. Bài tiếp theo mình sẽ hướng dẫn cài Open WebUI, một giao diện web đẹp giống ChatGPT để bạn chat với Ollama qua trình duyệt, có lịch sử hội thoại, nhiều model, upload file, và nhiều tính năng hay ho khác.
Có thể bạn cần xem thêm
- Chọn model AI phù hợp VPS - Llama vs Qwen vs DeepSeek vs Gemma
- n8n + Ollama - Tự động hóa workflow với AI chạy trên VPS riêng
- Chạy DeepSeek trên VPS không cần GPU - Hướng dẫn chi tiết với Ollama
- Ollama API - Tích hợp AI self-hosted vào ứng dụng web
- Cài Open WebUI + Ollama bằng Docker Compose - Tạo ChatGPT riêng trên VPS
- Gemma 4 là gì? Model AI mở mạnh nhất của Google chạy từ điện thoại đến server
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.