Bạn hỏi ChatGPT về quy trình nội bộ công ty, nó trả lời… bịa. Hỏi về tài liệu kỹ thuật riêng, nó hallucinate tự tin như thật. Không phải LLM ngáo, mà đơn giản là nó không có dữ liệu của bạn. RAG sinh ra để giải quyết đúng vấn đề này: cho LLM “đọc” tài liệu của bạn trước khi trả lời.
Bài này mình sẽ giải thích RAG là gì, cách nó hoạt động, và hướng dẫn 2 cách triển khai chatbot tài liệu nội bộ trên VPS mà không cần code.
RAG là gì?
RAG viết tắt của Retrieval Augmented Generation, dịch nôm na là “sinh nội dung có tra cứu hỗ trợ”.
Hình dung thế này: bạn hỏi một người bạn câu gì đó, thay vì trả lời ngay từ trí nhớ (có thể sai), người đó mở Google tra trước rồi mới trả lời. RAG hoạt động y vậy với LLM. Thay vì để model tự “bịa” từ kiến thức training, hệ thống sẽ tìm kiếm trong tài liệu của bạn trước, lấy đoạn liên quan nhất, rồi đưa cho LLM làm ngữ cảnh để trả lời.
Kết quả? Câu trả lời chính xác hơn, dựa trên dữ liệu thật, giảm hallucination đáng kể.
RAG hoạt động như thế nào?
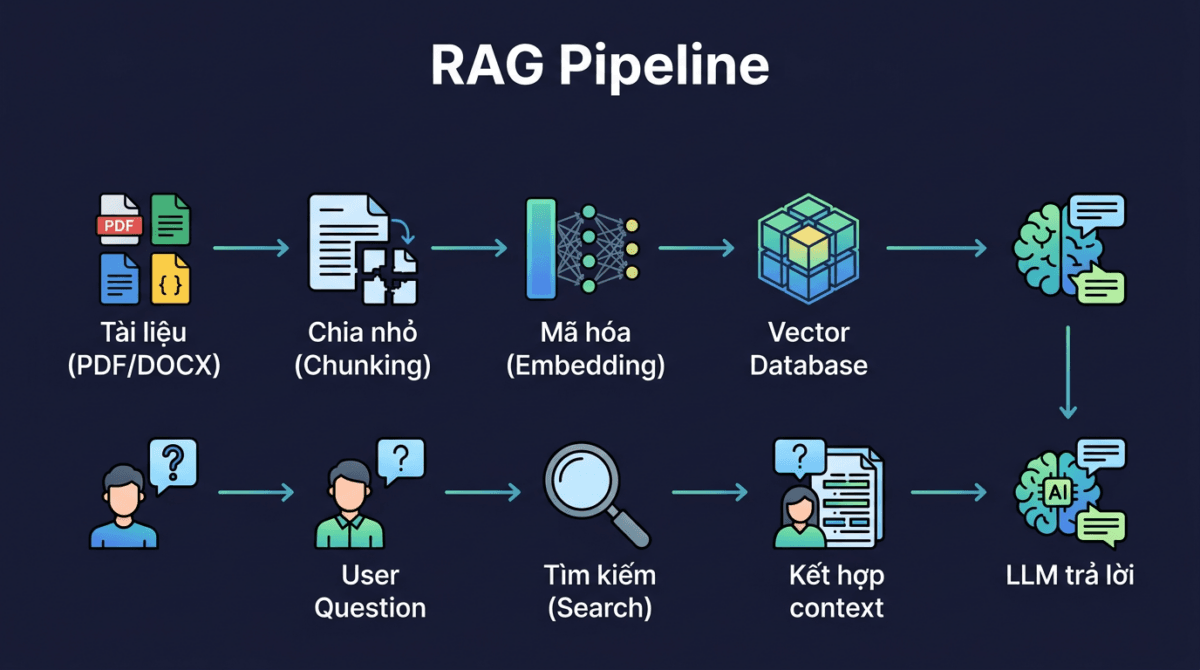
Flow của RAG gồm 2 giai đoạn chính:
Giai đoạn 1: Chuẩn bị dữ liệu (chạy 1 lần)
- Document – Thu thập tài liệu: PDF, DOCX, TXT, Markdown, hoặc crawl website
- Chunking – Cắt tài liệu thành từng đoạn nhỏ (chunk), thường 500-1000 token mỗi đoạn
- Embedding – Chuyển mỗi chunk thành vector (mảng số) đại diện cho ý nghĩa của đoạn text
- Vector DB – Lưu các vector vào database chuyên dụng để tìm kiếm nhanh
Giai đoạn 2: Trả lời câu hỏi (mỗi lần user hỏi)
- Query – Câu hỏi của user cũng được chuyển thành vector
- Search – Tìm các chunk có vector “gần” nhất với câu hỏi (semantic search)
- LLM – Ghép các chunk tìm được vào prompt, gửi cho LLM để sinh câu trả lời
Điểm hay của RAG là bạn không cần fine-tune model. Chỉ cần thêm tài liệu vào vector database, LLM sẽ biết cách dùng ngữ cảnh đó để trả lời. Thêm tài liệu mới? Upload thêm, không cần train lại gì cả.
Cách 1: Open WebUI built-in RAG (đơn giản nhất)
Nếu bạn đã cài Open WebUI theo các bài trước trong series, tin vui là nó đã có sẵn tính năng RAG. Không cần cài thêm gì.
Upload file trực tiếp trong chat
Cách nhanh nhất: kéo thả file PDF, DOCX, hoặc TXT vào ô chat. Open WebUI sẽ tự động parse, chunk, và embed nội dung. Sau đó bạn hỏi về nội dung file luôn trong cuộc chat đó.
Cách này phù hợp khi bạn cần hỏi nhanh về 1-2 file cụ thể. File chỉ có hiệu lực trong cuộc chat hiện tại.
Tạo Knowledge Base
Muốn dùng lại tài liệu cho nhiều cuộc chat? Tạo Knowledge Base:
- Vào Workspace → Knowledge
- Tạo collection mới, đặt tên (ví dụ: “Tài liệu nội bộ”)
- Upload các file vào collection
- Khi chat, gõ
#rồi chọn knowledge base muốn dùng
Mọi cuộc chat đều có thể truy cập knowledge base này, và bạn có thể thêm/xóa file bất cứ lúc nào.
Cấu hình RAG Settings
Vào Admin Panel → Settings → Documents để tinh chỉnh:
- Chunk Size: mặc định 1000 characters, tăng nếu tài liệu có đoạn dài cần giữ nguyên context
- Chunk Overlap: mặc định 100, giúp tránh mất thông tin ở ranh giới giữa 2 chunk
- Embedding Model: có thể chọn model embedding phù hợp. Với tiếng Việt,
nomic-embed-texthoặcbge-m3là lựa chọn ổn - Top K: số chunk lấy ra cho mỗi query, mặc định 4. Tăng nếu muốn câu trả lời bao quát hơn
Cách 2: AnythingLLM (all-in-one RAG)
Nếu bạn cần giải pháp RAG chuyên sâu hơn với nhiều tùy chọn vector database, quản lý workspace riêng biệt, và hỗ trợ nhiều loại data source, AnythingLLM là lựa chọn đáng thử.
Cài đặt bằng Docker
docker pull mintplexlabs/anythingllm
docker run -d \
--name anythingllm \
-p 3001:3001 \
-v anythingllm_storage:/app/server/storage \
--restart unless-stopped \
mintplexlabs/anythingllmTruy cập http://IP-VPS:3001, tạo tài khoản admin là xong bước setup.
Workflow cơ bản
- Kết nối LLM – Trong Settings → LLM Preference, trỏ về Ollama hoặc API provider bạn đang dùng
- Chọn Embedding Model – Có thể dùng Ollama embedding hoặc built-in model
- Tạo Workspace – Mỗi workspace là một “phòng chat” riêng với bộ tài liệu riêng
- Upload tài liệu – Hỗ trợ PDF, DOCX, TXT, CSV, và cả crawl website
- Chat – Hỏi đáp, AnythingLLM tự tìm context từ tài liệu đã upload
Điểm mạnh của AnythingLLM là giao diện quản lý tài liệu trực quan, hỗ trợ nhiều vector database backend, và có thể tạo nhiều workspace cho nhiều mục đích khác nhau (ví dụ: 1 workspace cho tài liệu HR, 1 workspace cho tài liệu kỹ thuật).
Vector Database: chọn cái nào?
Vector database là nơi lưu trữ các embedding vector. Cả Open WebUI và AnythingLLM đều có built-in vector DB, nhưng nếu bạn muốn scale hoặc dùng riêng, đây là 3 lựa chọn phổ biến:
pgvector (PostgreSQL extension)
Nếu bạn đang dùng PostgreSQL rồi thì đây là lựa chọn tự nhiên nhất. Chỉ cần cài extension pgvector, bạn có thể lưu vector ngay trong database quen thuộc. Không cần thêm service mới, backup chung với data khác, query bằng SQL quen thuộc. Phù hợp cho hầu hết use case vừa và nhỏ.
-- Cài pgvector extension
CREATE EXTENSION vector;
-- Tạo bảng lưu embeddings
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
);ChromaDB
Lightweight, chạy embedded hoặc client-server. Không cần setup database riêng, phù hợp cho prototype và project nhỏ. Open WebUI dùng ChromaDB làm backend mặc định.
Qdrant
Được thiết kế riêng cho production. Hỗ trợ filtering, multi-tenancy, và scale tốt. Nếu bạn build hệ thống RAG phục vụ nhiều người dùng hoặc dataset lớn (hàng triệu document), Qdrant là lựa chọn chắc chắn.
Với hầu hết trường hợp self-host trên VPS, built-in vector DB của Open WebUI hoặc AnythingLLM là đủ dùng. Chỉ cần quan tâm đến vector DB riêng khi bạn cần chia sẻ dữ liệu giữa nhiều ứng dụng hoặc dataset vượt quá vài GB.
Tips tối ưu RAG
RAG không phải “upload file rồi xong”. Chất lượng câu trả lời phụ thuộc rất nhiều vào cách bạn cấu hình:
- Chunk size: Quá nhỏ thì mất context, quá lớn thì lẫn nhiều thông tin không liên quan. Bắt đầu với 500-1000 characters rồi điều chỉnh theo kết quả thực tế
- Chunk overlap: Set 10-20% chunk size. Ví dụ chunk 1000 thì overlap 100-200. Giúp tránh trường hợp thông tin quan trọng bị cắt đúng ranh giới 2 chunk
- Embedding model: Model embedding quyết định chất lượng tìm kiếm. Với nội dung tiếng Việt, thử
bge-m3(đa ngôn ngữ, chạy được trên Ollama) hoặcnomic-embed-text - Định dạng tài liệu: Tài liệu có cấu trúc rõ ràng (heading, bullet points) cho kết quả tốt hơn nhiều so với wall of text. Nếu có file Word lộn xộn, cân nhắc format lại trước khi upload
- Top K: Số chunk đưa vào context. Nhiều quá thì tốn token và có thể gây nhiễu. Ít quá thì thiếu thông tin. 3-5 là điểm bắt đầu hợp lý
Use case thực tế
RAG không chỉ là là khái niệm xa vời. Dưới đây là vài cách dùng thực tế mà mình thấy nhiều người triển khai:
- FAQ Bot nội bộ: Upload toàn bộ FAQ, quy trình, policy vào knowledge base. Nhân viên mới hỏi chatbot thay vì hỏi đồng nghiệp lần thứ 100
- Knowledge base công ty: Tài liệu kỹ thuật, hướng dẫn sử dụng, SOP. Thay vì search Confluence/Notion rồi đọc 10 trang, hỏi chatbot lấy câu trả lời gọn
- Chatbot documentation: Cho tài liệu sản phẩm/API docs vào, khách hàng hoặc developer tự hỏi đáp. Giảm tải support team đáng kể
- Trợ lý nghiên cứu: Upload paper, báo cáo, sách. Hỏi chatbot tổng hợp, so sánh, tìm thông tin cụ thể thay vì đọc từng trang
- Legal/Compliance: Upload hợp đồng, quy định pháp lý. Chatbot giúp tra cứu điều khoản nhanh hơn nhiều so với tìm thủ công
Tổng kết
RAG là cầu nối giữa sức mạnh của LLM và dữ liệu riêng của bạn. Thay vì chấp nhận việc AI “bịa” khi không biết, bạn cho nó truy cập đúng nguồn thông tin cần thiết.
Với Open WebUI, bạn có RAG sẵn dùng chỉ bằng vài click upload. Với AnythingLLM, bạn có thêm tùy biến và quản lý workspace linh hoạt hơn. Cả hai đều chạy tốt trên VPS và không cần viết code.
Bắt đầu đơn giản: upload vài file tài liệu vào Open WebUI, thử hỏi đáp. Khi thấy kết quả chưa đủ tốt, tinh chỉnh chunk size, thử embedding model khác, hoặc cân nhắc chuyển sang AnythingLLM cho nhiều tùy chọn hơn.
Bài tiếp theo trong series, mình sẽ đi vào một chủ đề thực tế khác: cách dùng AI agents để tự động hóa workflow trên VPS.
Có thể bạn cần xem thêm
- Flowise là gì? Khi nào nên self-hosted trên VPS để tạo chatbot AI
- Cài đặt Dify AI trên VPS - No-code AI platform miễn phí
- n8n + AI: Xây dựng Workflow tự động với ChatGPT và LLMs
- Cài Open WebUI + Ollama bằng Docker Compose - Tạo ChatGPT riêng trên VPS
- MCP là gì? Cách AI Agent kết nối tool và dữ liệu bên ngoài
- Memory và Knowledge trong CrewAI: agent nhớ và học
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.