Mở Ollama lên, gõ ollama list thấy cả trăm model có thể pull về. Llama, Qwen, DeepSeek, Gemma, Phi, Mistral… mỗi cái lại có đủ biến thể 1B, 7B, 14B, 70B. Chưa kể quantization q4, q8, fp16. Người mới nhìn vào chắc chắn choáng.
Bài này mình sẽ giúp bạn hiểu rõ từng dòng model phổ biến nhất 2025, so sánh chúng với nhau, và quan trọng nhất: chọn model nào phù hợp với cấu hình VPS của bạn.
Cách đọc tên model trong Ollama
Trước khi đi vào so sánh, bạn cần biết cách đọc tên model. Lấy ví dụ:
qwen2.5:7b-instruct-q4_K_MTên này gồm 4 phần:
- qwen2.5 — Model family (dòng model, do Alibaba phát triển)
- 7b — Số lượng parameters (7 tỷ tham số). Số càng lớn thì model càng “thông minh” nhưng cũng càng ngốn RAM
- instruct — Biến thể đã fine-tune cho chat/instruction. Nếu không có thì là base model (dùng để train tiếp, không phải để chat)
- q4_K_M — Quantization level. Đây là kỹ thuật nén model để giảm RAM. q4 = 4-bit (nhẹ nhất), q8 = 8-bit (cân bằng), fp16 = full precision (nặng nhất, chất lượng cao nhất)
Mẹo: Khi dùng Ollama, mặc định pull về sẽ là bản q4_K_M. Đây là mức quantization cân bằng tốt giữa chất lượng và dung lượng RAM. Bạn không cần thay đổi gì trừ khi có yêu cầu đặc biệt.
Các dòng model phổ biến nhất hiện nay
Dưới đây là 6 dòng model mà bạn sẽ gặp nhiều nhất khi self-host AI trên VPS.
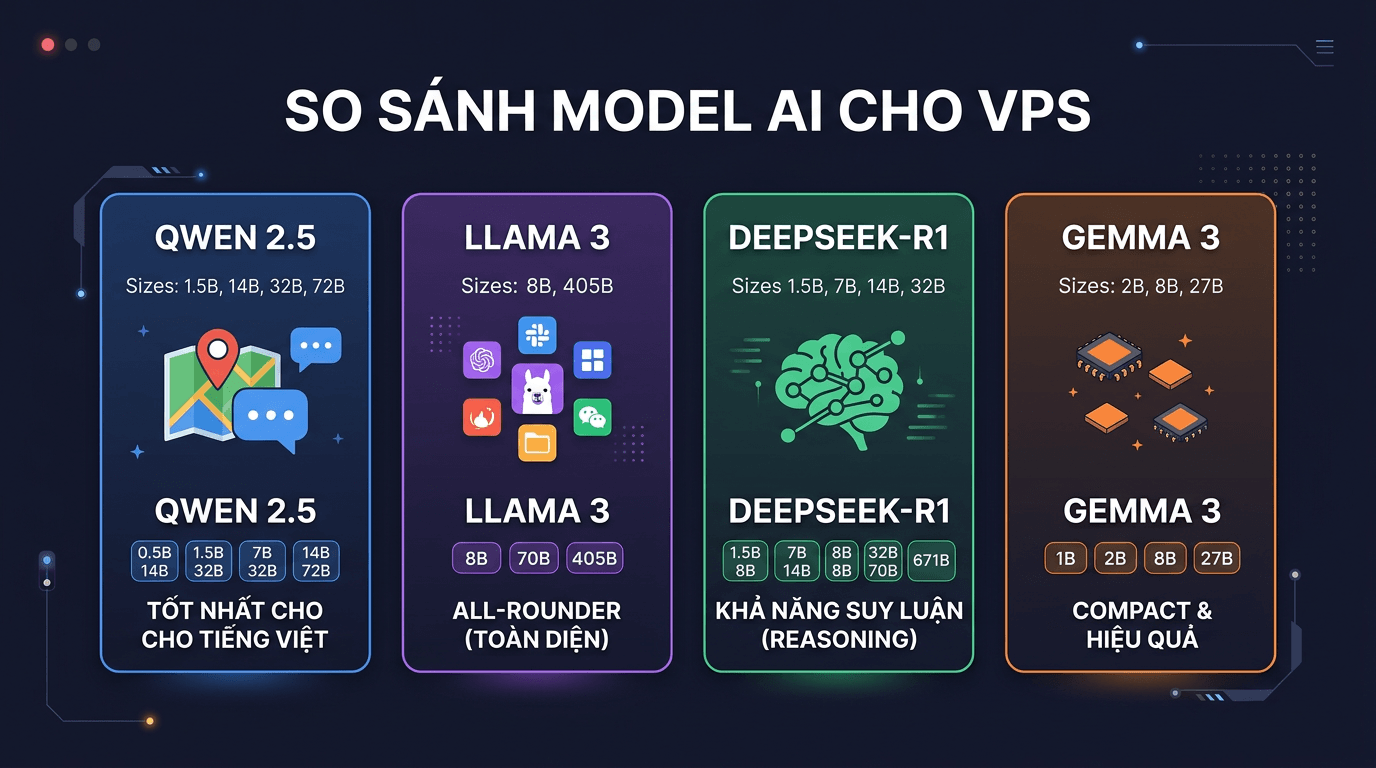
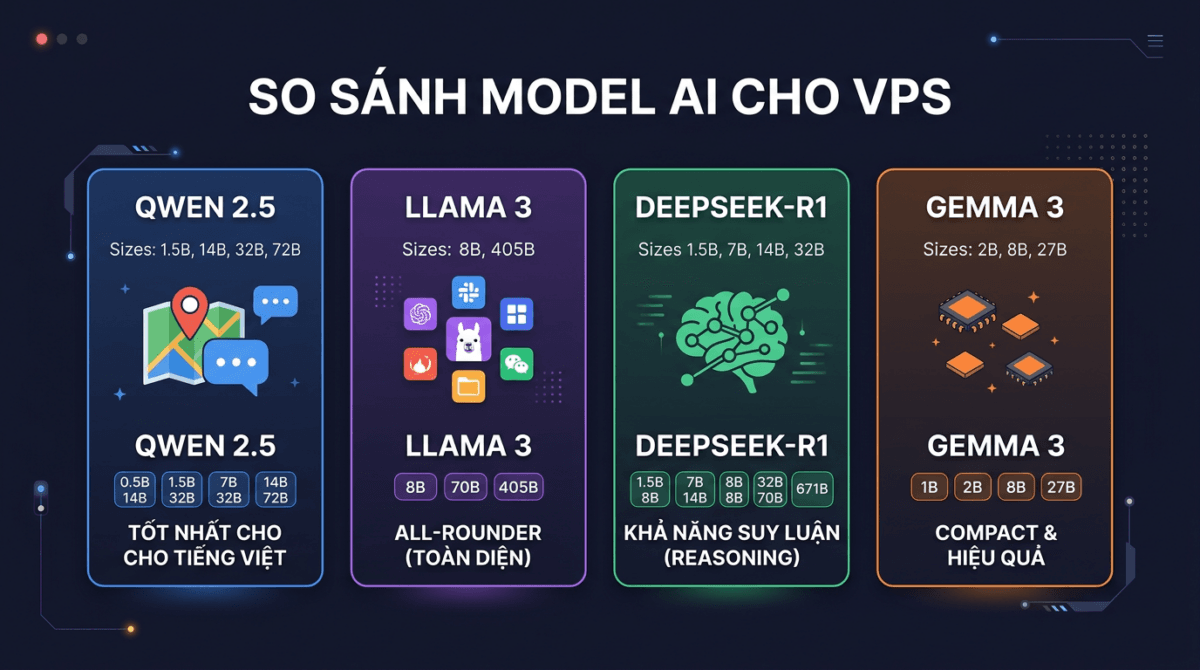
Qwen 2.5 (Alibaba)
Đây là dòng model mình recommend nhiều nhất cho người dùng Việt Nam. Qwen 2.5 được Alibaba train với lượng dữ liệu đa ngôn ngữ rất lớn, bao gồm cả tiếng Việt. Kết quả là nó hiểu và trả lời tiếng Việt tốt hơn hẳn so với các model cùng size.
- Size: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B
- License: Apache 2.0 (thoải mái dùng thương mại)
- Điểm mạnh: Tiếng Việt xuất sắc, có bản Coder riêng cho lập trình, đa dạng size
- Điểm yếu: Reasoning chưa bằng DeepSeek-R1 ở cùng size
Llama 3.x (Meta)
Llama là dòng model “quốc dân” của cộng đồng open-source AI. Meta đầu tư rất mạnh và cộng đồng support cũng đông nhất. Hầu hết tool, framework, tutorial đều lấy Llama làm model mặc định.
- Size: 1B, 3B, 8B, 70B, 405B
- License: Llama Community License (miễn phí cho hầu hết use case, hạn chế nếu trên 700 triệu MAU)
- Điểm mạnh: All-rounder, cộng đồng lớn, tài liệu nhiều, ổn định
- Điểm yếu: Tiếng Việt không bằng Qwen, bản 70B+ rất nặng
DeepSeek-R1 (DeepSeek)
DeepSeek-R1 là model chuyên về reasoning (suy luận). Nó sử dụng chain-of-thought, nghĩa là model sẽ “suy nghĩ từng bước” trước khi đưa ra câu trả lời. Rất phù hợp cho các bài toán logic, phân tích, và lập trình phức tạp.
- Size: 1.5B, 7B, 8B, 14B, 32B, 70B (distill versions)
- License: MIT
- Điểm mạnh: Reasoning vượt trội, coding tốt, suy luận logic chặt chẽ
- Điểm yếu: Output dài hơn (do chain-of-thought), tốc độ chậm hơn model thường cùng size
Gemma 3 (Google)
Google tham gia cuộc chơi open-weight với Gemma. Điểm nổi bật là chất lượng rất tốt cho size nhỏ. Nếu bạn có VPS cấu hình thấp mà vẫn muốn chất lượng ổn, Gemma đáng để thử.
- Size: 1B, 4B, 12B, 27B
- License: Gemma License (tương tự Apache, cho phép thương mại)
- Điểm mạnh: Compact, hiệu quả cao so với size, multimodal (hỗ trợ hình ảnh)
- Điểm yếu: Tiếng Việt trung bình, ít size lựa chọn
Phi-3.5 / Phi-4 (Microsoft)
Microsoft tập trung vào hướng “small but mighty”. Phi-3.5 chỉ 3.8B parameters nhưng benchmark đánh bại nhiều model 7B. Nếu bạn chỉ có VPS 4GB RAM, đây là lựa chọn rất đáng cân nhắc.
- Size: 3.8B (Phi-3.5), 14B (Phi-4)
- License: MIT
- Điểm mạnh: Cực nhẹ, chất lượng cao so với size, MIT license
- Điểm yếu: Ít size lựa chọn, tiếng Việt hạn chế, cộng đồng nhỏ hơn
Mistral / Mixtral (Mistral AI)
Startup Pháp nổi tiếng với kiến trúc Mixture of Experts (MoE). Mixtral 8x7B có tổng 47B parameters nhưng mỗi lần inference chỉ activate 13B, nên tốc độ nhanh mà chất lượng vẫn cao.
- Size: 7B (Mistral), 8x7B / 8x22B (Mixtral)
- License: Apache 2.0
- Điểm mạnh: Nhanh, kiến trúc MoE hiệu quả, coding tốt
- Điểm yếu: Mixtral cần nhiều RAM (dù inference nhanh), tiếng Việt trung bình
Bảng so sánh tổng quan
Bảng dưới đây so sánh các model ở size phổ biến nhất (7B-14B), chạy quantization q4_K_M trên CPU:
| Model | Size | RAM cần (q4) | License | Tiếng Việt | Coding | Reasoning |
|---|---|---|---|---|---|---|
| Qwen 2.5 7B | 7B | ~5.5 GB | Apache 2.0 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Llama 3.1 8B | 8B | ~6 GB | Llama License | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| DeepSeek-R1 8B | 8B | ~6 GB | MIT | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Gemma 3 12B | 12B | ~8 GB | Gemma License | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Phi-3.5 | 3.8B | ~3 GB | MIT | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Mistral 7B | 7B | ~5.5 GB | Apache 2.0 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| Qwen 2.5 14B | 14B | ~10 GB | Apache 2.0 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| DeepSeek-R1 14B | 14B | ~10 GB | MIT | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
Chọn model theo cấu hình VPS
Đây là phần quan trọng nhất. Model hay đến mấy mà VPS không đủ RAM thì cũng vô nghĩa. Dưới đây là gợi ý cụ thể theo từng mức cấu hình:
VPS 4GB RAM: Chạy được, nhưng phải chọn kỹ
Với 4GB RAM, bạn cần để lại khoảng 1GB cho hệ điều hành và Ollama, còn lại ~3GB cho model. Lựa chọn tốt nhất:
- Qwen 2.5 3B (q4_K_M) ~ 2.3 GB: Chất lượng tiếng Việt tốt nhất ở phân khúc này
- Phi-3.5 3.8B (q4_K_M) ~ 2.8 GB: Benchmark cao hơn nhưng tiếng Việt yếu hơn
- Gemma 3 1B (q4_K_M) ~ 1 GB: Cực nhẹ, phù hợp task đơn giản
VPS 8GB RAM: Sweet spot cho người mới
8GB RAM là mức mình khuyên bắt đầu nếu nghiêm túc muốn self-host AI. Bạn chạy được hầu hết model 7-8B với chất lượng tốt:
- Qwen 2.5 7B (q4_K_M) ~ 5.5 GB: Lựa chọn số 1 nếu dùng tiếng Việt
- Llama 3.1 8B (q4_K_M) ~ 6 GB: All-rounder, tài liệu và cộng đồng đông
- DeepSeek-R1 8B (q4_K_M) ~ 6 GB: Nếu cần reasoning mạnh
- Gemma 3 4B (q4_K_M) ~ 3 GB: Nhẹ, chừa RAM cho ứng dụng khác
VPS 16GB RAM: Bước lên đẳng cấp mới
Với 16GB, bạn mở được cánh cửa model 14B. Đây là mức mà chất lượng output bắt đầu thực sự ấn tượng:
- Qwen 2.5 14B (q4_K_M) ~ 10 GB: Best pick. Tiếng Việt + coding + reasoning đều tốt
- DeepSeek-R1 14B (q4_K_M) ~ 10 GB: Reasoning cực mạnh ở mức này
- Gemma 3 12B (q4_K_M) ~ 8 GB: Nhẹ hơn, chạy nhanh hơn
VPS 32GB+ RAM: Chạy model lớn
32GB RAM cho phép chạy model 32B trên CPU, nhưng tốc độ sẽ chậm. Nếu muốn trải nghiệm mượt ở size này, bạn nên có GPU:
- Qwen 2.5 32B (q4_K_M) ~ 22 GB: Chất lượng gần model thương mại
- DeepSeek-R1 32B (q4_K_M) ~ 22 GB: Reasoning ngang ngửa model lớn hơn nhiều
- Gemma 3 27B (q4_K_M) ~ 18 GB: Tốt, nhẹ hơn một chút
Lưu ý: Các con số RAM ở trên là ước tính cho model quantization q4_K_M chạy trên CPU. Thực tế có thể dao động tùy context length và hệ điều hành. Bạn nên để dư ít nhất 1-2 GB RAM cho hệ thống.
Chọn model theo use case
Ngoài cấu hình phần cứng, bạn cũng nên chọn model theo mục đích sử dụng chính:
Chat và xử lý tiếng Việt → Qwen 2.5
Nếu bạn cần chatbot trả lời tiếng Việt, viết nội dung tiếng Việt, hoặc xử lý tài liệu tiếng Việt, thì Qwen 2.5 là lựa chọn rõ ràng nhất. Ở mọi size từ 3B đến 72B, khả năng tiếng Việt của Qwen đều vượt trội so với đối thủ cùng hạng.
Lập trình / Coding → DeepSeek hoặc Qwen 2.5 Coder
Cần AI hỗ trợ viết code? Hai lựa chọn hàng đầu:
- DeepSeek-R1: Suy luận logic tốt, debug giỏi, hiểu bài toán phức tạp
- Qwen 2.5 Coder: Bản chuyên biệt cho coding, hỗ trợ nhiều ngôn ngữ lập trình, có version 7B chạy trên VPS 8GB thoải mái
Suy luận và phân tích → DeepSeek-R1
Bài toán logic, phân tích dữ liệu, giải thích vấn đề phức tạp? DeepSeek-R1 với chain-of-thought sẽ cho output chất lượng hơn hẳn. Đổi lại, response sẽ dài hơn và chậm hơn vì model cần “suy nghĩ” trước khi trả lời.
Đa mục đích / General → Llama 3.1
Nếu bạn không có nhu cầu cụ thể và muốn một model làm được tất cả ở mức khá, Llama 3.1 8B là sự lựa chọn an toàn. Cộng đồng lớn, tài liệu nhiều, gặp lỗi dễ tìm được giải pháp.
Test thực tế: Cùng 1 prompt, 4 model trả lời khác nhau thế nào?
Mình thử test với cùng một prompt tiếng Việt trên 4 model phổ biến (đều ở size ~7-8B, quantization q4_K_M) để bạn thấy sự khác biệt rõ hơn:
Prompt: “Giải thích cách hoạt động của DNS bằng ngôn ngữ đơn giản, khoảng 3-4 câu.”
Qwen 2.5 7B: Trả lời tự nhiên, đúng ngữ pháp tiếng Việt, giải thích rõ ràng. Không bị lỗi từ vựng hay câu lủng củng. Đây là output mà bạn có thể dùng ngay mà không cần chỉnh sửa nhiều.
Llama 3.1 8B: Nội dung đúng nhưng câu văn tiếng Việt hơi “dịch máy”. Một số cụm từ không tự nhiên lắm. Vẫn dùng được nhưng cần review lại.
DeepSeek-R1 8B: Trả lời rất chi tiết, có phần suy luận dài trước khi đưa câu trả lời chính. Chất lượng nội dung tốt nhưng response dài hơn nhiều so với yêu cầu. Tiếng Việt ở mức khá.
Gemma 3 4B: Ngắn gọn, đúng trọng tâm. Tiếng Việt đôi chỗ hơi cứng nhưng chấp nhận được cho model chỉ 4B. Tốc độ trả lời nhanh nhất trong 4 model.
Tổng kết: Nên chọn model nào?
Sau khi test và so sánh, đây là khuyến nghị của mình:
- Mới bắt đầu, muốn đơn giản: Cứ
ollama pull qwen2.5:7brồi dùng. Đây là lựa chọn tốt nhất cho đa số người dùng Việt Nam. - VPS yếu (4GB RAM):
ollama pull qwen2.5:3bhoặcollama pull phi3.5 - Cần coding assistant:
ollama pull qwen2.5-coder:7bhoặcollama pull deepseek-r1:8b - Muốn chất lượng cao nhất (16GB RAM):
ollama pull qwen2.5:14b - Muốn thử nhiều model: Cứ pull 2-3 model rồi test cùng prompt. Ollama cho phép chuyển model dễ dàng, không cần commit với một model nào cả.
Tip: Bạn có thể cài nhiều model cùng lúc trên Ollama. Chỉ cần ổ cứng đủ chỗ là được. Ollama chỉ load model vào RAM khi bạn thực sự sử dụng, và tự giải phóng sau vài phút không dùng.
Thế giới AI model đang phát triển cực nhanh. Cứ vài tháng lại có model mới tốt hơn. Nhưng với những gì hiện có, Qwen 2.5 đang là lựa chọn toàn diện nhất cho người dùng Việt Nam self-host AI trên VPS. Hãy bắt đầu với nó, rồi thử các model khác khi bạn đã quen.
Có thể bạn cần xem thêm
- Chạy DeepSeek trên VPS không cần GPU - Hướng dẫn chi tiết với Ollama
- Cài đặt Ollama trên VPS Ubuntu - Chạy AI riêng trong 15 phút
- Gemma 4 là gì? Model AI mở mạnh nhất của Google chạy từ điện thoại đến server
- n8n + Ollama - Tự động hóa workflow với AI chạy trên VPS riêng
- Cài Open WebUI + Ollama bằng Docker Compose - Tạo ChatGPT riêng trên VPS
- Ollama API - Tích hợp AI self-hosted vào ứng dụng web
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.