
DeepSeek đang là cái tên được nhắc đến nhiều nhất trong giới AI gần đây. Model reasoning mạnh, miễn phí, mã nguồn mở. Nhưng có một vấn đề: nếu bạn dùng API của DeepSeek, dữ liệu của bạn sẽ được gửi về server ở Trung Quốc. Với nhiều người, đặc biệt là khi xử lý dữ liệu nhạy cảm của công ty hay khách hàng, đây là điều không chấp nhận được.
Giải pháp? Tự chạy DeepSeek trên server của mình. Và tin vui là bạn không cần GPU đắt tiền để làm điều này. Một VPS Linux bình thường với CPU và vài GB RAM là đủ để chạy các phiên bản nhỏ của DeepSeek-R1 thông qua Ollama.
Trong bài này, mình sẽ hướng dẫn bạn cách chạy DeepSeek-R1 trên VPS không có GPU, thử nghiệm thực tế trên VPS 4 vCPU / 4GB RAM, và chia sẻ một số mẹo tối ưu hiệu năng.
Bài viết này là phần 3 trong series “Chạy AI trên VPS”. Nếu bạn chưa cài Ollama, hãy xem lại bài 1: Cài đặt Ollama trên VPS trước nhé.
DeepSeek-R1 là gì?
DeepSeek-R1 là model AI do DeepSeek (Trung Quốc) phát triển, nổi bật nhờ khả năng “chain-of-thought reasoning”. Nói đơn giản, thay vì trả lời ngay, model sẽ tự suy nghĩ từng bước trước khi đưa ra câu trả lời cuối cùng. Bạn có thể thấy quá trình suy nghĩ này trong tag <think>...</think> khi chat.
Model gốc DeepSeek-R1 có 671 tỷ tham số (671B), cần hàng trăm GB VRAM để chạy. Nhưng DeepSeek cũng phát hành các phiên bản “distilled” (chưng cất) nhỏ hơn rất nhiều. Các phiên bản này được huấn luyện lại từ model gốc, giữ được phần lớn khả năng reasoning nhưng kích thước nhỏ hơn hàng chục lần. Đây chính là những phiên bản mà chúng ta có thể chạy trên CPU.
Các phiên bản chạy được trên VPS
Ollama hỗ trợ sẵn các phiên bản distilled của DeepSeek-R1. Dưới đây là 3 phiên bản phổ biến nhất và yêu cầu phần cứng tương ứng:
| Model | Kích thước | RAM tối thiểu | Ghi chú |
|---|---|---|---|
deepseek-r1:1.5b | ~1.1 GB | 4 GB | Chạy tốt trên VPS nhỏ, phù hợp test và task đơn giản |
deepseek-r1:7b | ~4.7 GB | 8 GB | Cân bằng giữa chất lượng và tài nguyên |
deepseek-r1:14b | ~9 GB | 16 GB | Chất lượng reasoning tốt hơn rõ rệt |
Lưu ý: RAM tối thiểu ở trên bao gồm cả hệ điều hành. Ví dụ VPS 4GB RAM thực tế chỉ còn khoảng 3.5-3.8GB khả dụng, vẫn đủ chạy bản 1.5b.
Tải và chạy DeepSeek-R1
Nếu bạn đã cài Ollama theo bài trước, việc tải DeepSeek-R1 chỉ cần một lệnh:
ollama pull deepseek-r1:1.5bĐợi vài phút để tải xong (tùy tốc độ mạng), sau đó chạy thử:
ollama run deepseek-r1:1.5b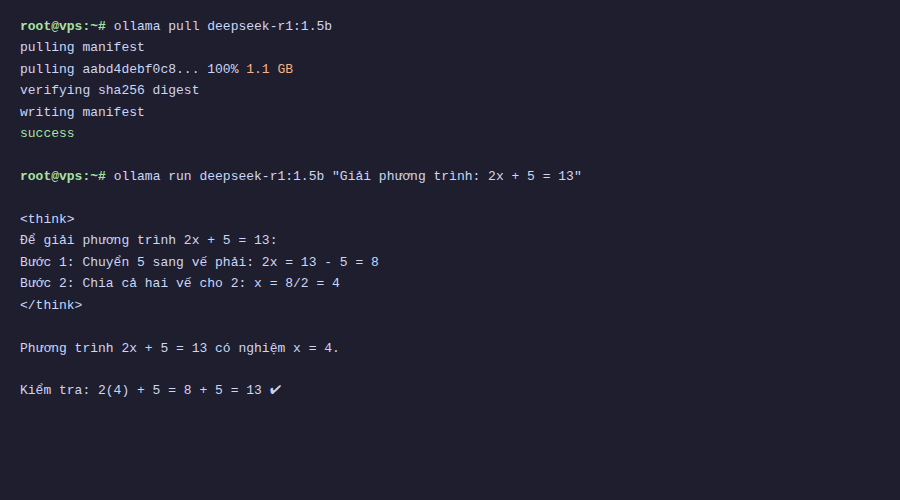
Test khả năng reasoning
Điểm mạnh của DeepSeek-R1 là reasoning, tức khả năng suy luận logic. Mình thử hỏi một câu toán đơn giản để xem model xử lý thế nào:
>>> Nếu mình có 3 quả táo, cho bạn 1 quả, rồi mua thêm 5 quả, thì mình có bao nhiêu quả?Với DeepSeek-R1, bạn sẽ thấy model hiển thị phần <think> trước, liệt kê từng bước tính, rồi mới đưa ra kết quả. Đây là điểm khác biệt lớn so với các model thông thường như Qwen hay Llama, những model trả lời thẳng mà không show quá trình suy nghĩ.
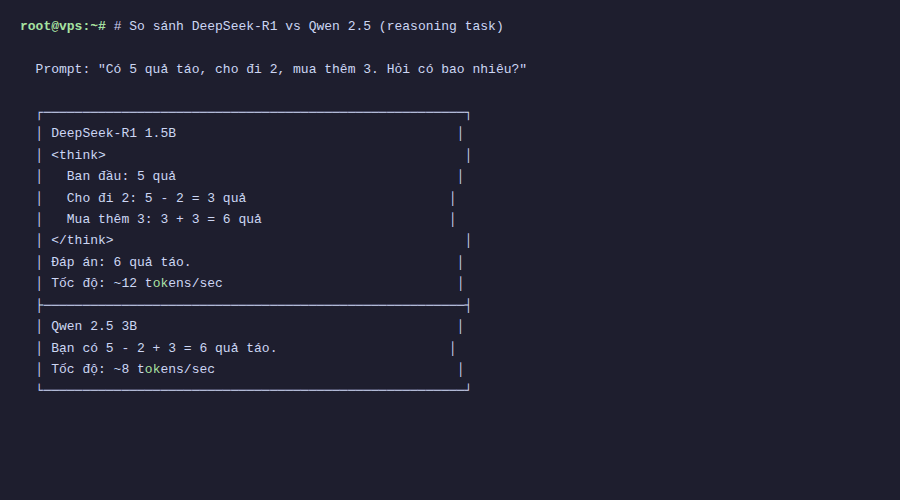
Tất nhiên, bản 1.5b vẫn là model nhỏ nên đôi khi nó suy luận sai hoặc lặp vòng trong phần think. Bản 7b và 14b cho kết quả reasoning chính xác hơn nhiều, nhưng cũng cần nhiều RAM hơn.
Quantization là gì? Tại sao model chạy được trên CPU?
Bạn có thể thắc mắc: model 1.5 tỷ tham số mà chỉ chiếm 1.1GB là sao? Câu trả lời là quantization.
Khi huấn luyện, mỗi tham số của model được lưu dưới dạng số thực 16-bit (FP16) hoặc 32-bit. Một model 1.5B tham số ở FP16 sẽ chiếm khoảng 3GB. Quantization là quá trình giảm độ chính xác của các tham số này xuống, ví dụ:
- Q4_K_M: mỗi tham số chỉ dùng ~4 bit. Giảm kích thước rất nhiều, chất lượng giảm nhẹ. Đây là mức mặc định mà Ollama sử dụng.
- Q8_0: mỗi tham số dùng 8 bit. File lớn hơn Q4 nhưng chất lượng tốt hơn.
- FP16: giữ nguyên 16-bit, chất lượng gần như gốc nhưng file rất lớn.
Ollama dùng format GGUF (do llama.cpp phát triển), được thiết kế đặc biệt để chạy model trên CPU hiệu quả. Nhờ GGUF và quantization Q4, một model 7B có thể nén xuống còn ~4.7GB và chạy được trên CPU mà không cần GPU.
Benchmark thực tế trên VPS CPU-only
Mình test trên VPS 4 vCPU, 3.8GB RAM, Ubuntu 24.04, không có GPU. Ollama phiên bản 0.18.0.
Với deepseek-r1:1.5b, tốc độ generate khoảng 15-25 token/giây. Đủ để đọc thoải mái, tương đương tốc độ đánh máy nhanh. Phần “think” thường mất 5-15 giây tùy câu hỏi, sau đó model bắt đầu trả lời.
Nếu bạn hỏi câu phức tạp và model “nghĩ” dài (vài trăm token trong phần think), thời gian chờ có thể lên 30-60 giây. Đây là trade-off khi chạy trên CPU: bạn được privacy và miễn phí, nhưng phải chấp nhận tốc độ chậm hơn so với GPU hoặc API.
Một lưu ý quan trọng: lần chạy đầu tiên sau khi pull model sẽ mất vài giây để load model vào RAM. Các lần chạy tiếp theo sẽ nhanh hơn vì Ollama giữ model trong memory.
DeepSeek vs Qwen vs Llama: khi nào dùng gì?
Nếu bạn đã đọc các bài trước trong series, bạn đã thử Qwen 2.5. Vậy khi nào nên dùng model nào?
- DeepSeek-R1: dùng khi cần suy luận logic, toán, phân tích code, hoặc bất kỳ task nào cần model “nghĩ kỹ” trước khi trả lời. Nhược điểm là chậm hơn vì có thêm bước think.
- Qwen 2.5: tốt cho chat tổng quát, viết nội dung, trả lời tiếng Việt. Nhanh hơn DeepSeek-R1 ở cùng kích thước vì không có bước reasoning.
- Llama 3: mạnh với tiếng Anh, code generation. Hỗ trợ tiếng Việt kém hơn Qwen.
Thực tế, bạn có thể cài nhiều model cùng lúc trên Ollama và chuyển đổi tùy nhu cầu. Ollama sẽ tự quản lý việc load/unload model trong RAM.
Mẹo tối ưu khi chạy trên VPS
Sau khi chạy thử một thời gian, mình rút ra vài mẹo giúp DeepSeek-R1 chạy mượt hơn trên VPS tài nguyên hạn chế:
Giới hạn số request song song
Mặc định Ollama cho phép nhiều request cùng lúc. Trên VPS nhỏ, điều này dễ gây hết RAM. Bạn nên giới hạn về 1:
export OLLAMA_NUM_PARALLEL=1Hoặc thêm vào file systemd service của Ollama để áp dụng cố định.
Giảm context length
Context length dài hơn thì tốn RAM hơn. Nếu bạn chỉ cần chat ngắn, có thể giới hạn context khi chạy:
ollama run deepseek-r1:1.5b --ctx-size 2048Theo dõi RAM usage
Dùng htop hoặc free -h để theo dõi RAM khi model đang chạy. Nếu thấy swap bắt đầu được sử dụng nhiều, model sẽ chạy rất chậm. Lúc này bạn nên dùng model nhỏ hơn hoặc nâng cấp VPS.
# Kiểm tra RAM usage
free -h
# Xem process Ollama chiếm bao nhiêu RAM
ps aux | grep ollamaTự động unload model
Ollama giữ model trong RAM sau khi chat xong (mặc định 5 phút). Trên VPS nhỏ, bạn có thể giảm thời gian này:
export OLLAMA_KEEP_ALIVE=60 # unload sau 60 giây không dùngTổng kết
DeepSeek-R1 là một lựa chọn rất tốt nếu bạn cần khả năng reasoning mà không muốn gửi dữ liệu ra ngoài. Phiên bản 1.5b chạy thoải mái trên VPS 4GB RAM, còn bản 7b chạy được trên VPS 8GB. Tốc độ trên CPU không nhanh bằng GPU, nhưng đủ dùng cho nhiều tác vụ thực tế.
Kết hợp với Qwen 2.5 cho chat tổng quát và DeepSeek-R1 cho reasoning, bạn đã có một bộ công cụ AI khá đầy đủ chạy hoàn toàn trên VPS của mình.
Ở bài tiếp theo, mình sẽ hướng dẫn cách kết nối Ollama với các ứng dụng như Open WebUI để có giao diện chat đẹp hơn, và cách expose API của Ollama để dùng từ xa an toàn. Hẹn gặp bạn ở bài sau!
Có thể bạn cần xem thêm
- Chọn model AI phù hợp VPS - Llama vs Qwen vs DeepSeek vs Gemma
- Cài đặt Ollama trên VPS Ubuntu - Chạy AI riêng trong 15 phút
- n8n + Ollama - Tự động hóa workflow với AI chạy trên VPS riêng
- Gemma 4 là gì? Model AI mở mạnh nhất của Google chạy từ điện thoại đến server
- vLLM là gì? Khi nào nên dùng vLLM thay Ollama
- vLLM là gì? Khi nào nên dùng vLLM thay Ollama
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.