Agent trong CrewAI biết cách làm việc, nhưng cần có Task để biết làm gì. Task định nghĩa nhiệm vụ cụ thể, kết quả mong đợi, và Agent nào chịu trách nhiệm. Bài này hướng dẫn bạn tạo Task từ đơn giản đến phức tạp, bao gồm cả cách kết nối các Task thành pipeline hoàn chỉnh.
Nếu bạn chưa nắm cách tạo Agent, hãy đọc bài hướng dẫn Agent trong CrewAI trước. Để xem tổng quan framework, tham khảo bài giới thiệu CrewAI từ A-Z.
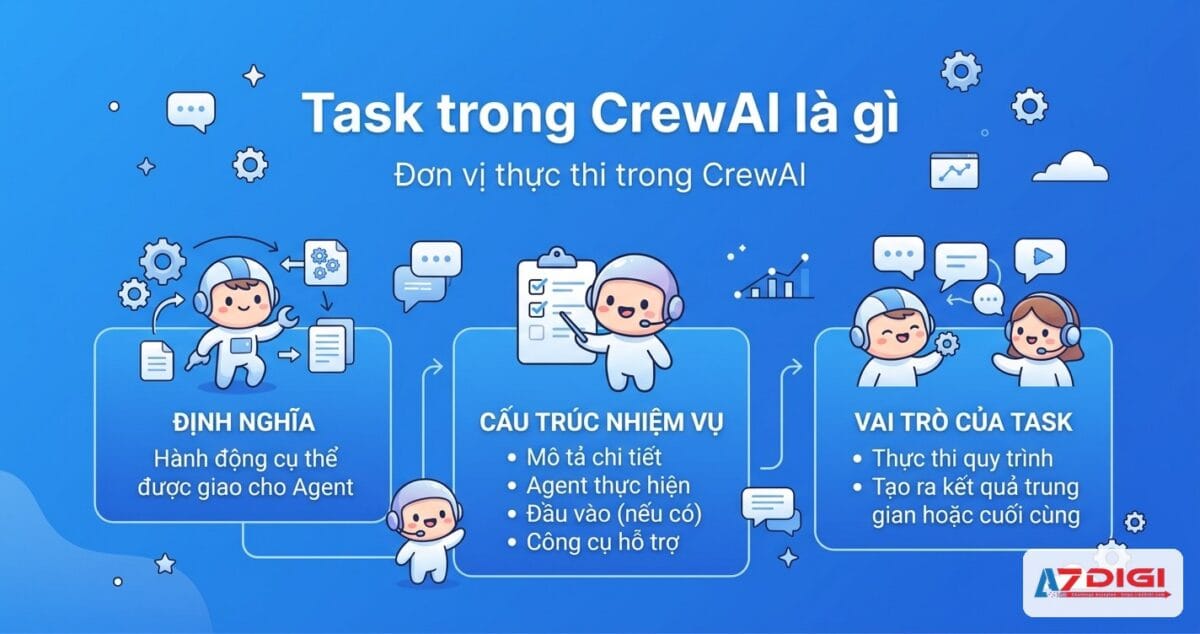
Task trong CrewAI là gì

Task là một đơn vị công việc trong CrewAI. Mỗi Task mô tả rõ ràng: cần làm gì, ai làm, và kết quả trả về ra sao.
Khi Crew chạy, các Task được thực thi theo thứ tự hoặc phân phối tự động tùy vào Process bạn chọn:
- Sequential: Task chạy lần lượt theo thứ tự khai báo. Output của task trước có thể làm input cho task sau.
- Hierarchical: Manager Agent tự phân công Task cho Agent phù hợp dựa trên role và khả năng.
Một Task tốt cần đáp ứng 2 tiêu chí: mô tả đủ chi tiết để Agent hiểu cần làm gì, và định nghĩa rõ output mong đợi để đánh giá kết quả.
Thuộc tính chính của Task

Mỗi Task có 2 thuộc tính bắt buộc và nhiều thuộc tính tùy chọn.
Thuộc tính bắt buộc
- description: Mô tả chi tiết nhiệm vụ. Đây là phần Agent sẽ đọc để hiểu cần làm gì. Viết càng cụ thể, Agent càng cho kết quả chính xác.
- expected_output: Mô tả kết quả mong đợi. Agent dùng thông tin này để biết khi nào đã hoàn thành Task. Ví dụ: “Danh sách 10 ý chính dạng bullet point” rõ ràng hơn “Một bản tóm tắt”.
Thuộc tính tùy chọn quan trọng
| Thuộc tính | Kiểu dữ liệu | Mô tả |
|---|---|---|
| agent | Agent | Agent chịu trách nhiệm thực thi Task. Nếu không chỉ định, Crew sẽ tự gán. |
| context | List[Task] | Danh sách Task khác, output của chúng sẽ làm ngữ cảnh cho Task hiện tại. |
| tools | List[BaseTool] | Danh sách tool mà Agent được dùng cho Task này (ghi đè tool mặc định của Agent). |
| output_file | str | Đường dẫn file để lưu kết quả Task. |
| output_json | BaseModel | Pydantic model để ép output theo cấu trúc JSON. |
| output_pydantic | BaseModel | Pydantic model để ép output thành object Python. |
| async_execution | bool | Cho phép Task chạy bất đồng bộ. Mặc định False. |
| human_input | bool | Yêu cầu người dùng duyệt kết quả trước khi hoàn tất. Mặc định False. |
| callback | Callable | Hàm chạy sau khi Task hoàn thành. |
| guardrail | Callable | Hàm kiểm tra output trước khi chuyển sang Task tiếp theo. |
YAML và Python: hai cách định nghĩa Task

Giống Agent, Task cũng hỗ trợ cả YAML và Python. CrewAI khuyến nghị dùng YAML để tách cấu hình khỏi code.
Định nghĩa Task bằng YAML
# config/tasks.yaml - Khai báo task bằng YAML
research_task:
description: >
Nghiên cứu thông tin mới nhất về {topic}.
Tập trung vào các xu hướng nổi bật trong năm 2025.
Kiểm chứng từ ít nhất 3 nguồn đáng tin cậy.
expected_output: >
Danh sách 10 điểm chính dạng bullet point,
mỗi điểm kèm nguồn tham khảo.
agent: researcher
writing_task:
description: >
Dựa trên kết quả nghiên cứu, viết bài blog chi tiết
về {topic}. Bài viết cần dài 1500-2000 từ, chia
thành các phần rõ ràng với heading.
expected_output: >
Bài viết hoàn chỉnh dạng Markdown, có mục lục,
heading rõ ràng, và kết luận.
agent: writer
output_file: output/article.mdBiến {topic} sẽ được thay thế khi gọi crew.kickoff(inputs={'topic': 'AI Agents'}).
Định nghĩa Task bằng Python
# Tạo task trực tiếp bằng Python
from crewai import Task
research_task = Task(
description="""
Nghiên cứu thông tin mới nhất về AI Agents.
Tập trung vào xu hướng nổi bật năm 2025.
Kiểm chứng từ ít nhất 3 nguồn.
""",
expected_output="""
Danh sách 10 điểm chính dạng bullet point,
mỗi điểm kèm nguồn tham khảo.
""",
agent=researcher # Gán agent chịu trách nhiệm
)
writing_task = Task(
description="""
Viết bài blog chi tiết dựa trên kết quả nghiên cứu.
Bài viết 1500-2000 từ, chia heading rõ ràng.
""",
expected_output="Bài viết hoàn chỉnh dạng Markdown",
agent=writer,
output_file="output/article.md" # Tự lưu kết quả ra file
)Dùng YAML khi dự án có nhiều Task cần quản lý. Dùng Python khi cần tạo Task động, ví dụ Task phụ thuộc vào input từ người dùng lúc runtime.
Task phụ thuộc nhau với context

Trong thực tế, các Task thường liên quan đến nhau. Task viết bài cần dữ liệu từ Task nghiên cứu. Task kiểm duyệt cần đọc bài viết từ Task viết. CrewAI xử lý điều này qua thuộc tính context.
Khi bạn truyền một danh sách Task vào context, output của các Task đó sẽ được đưa vào prompt cho Agent xử lý Task hiện tại.
# Tạo chuỗi task phụ thuộc nhau
from crewai import Task
# Task 1: Nghiên cứu (không phụ thuộc task nào)
research_task = Task(
description="Nghiên cứu xu hướng AI mới nhất",
expected_output="10 xu hướng AI quan trọng nhất",
agent=researcher
)
# Task 2: Viết bài (cần kết quả từ Task 1)
writing_task = Task(
description="Viết bài blog dựa trên kết quả nghiên cứu",
expected_output="Bài viết 2000 từ dạng Markdown",
agent=writer,
context=[research_task] # Nhận output từ research_task
)
# Task 3: Kiểm duyệt (cần kết quả từ cả Task 1 và Task 2)
review_task = Task(
description="Kiểm tra bài viết về độ chính xác và chất lượng",
expected_output="Bài viết đã chỉnh sửa kèm ghi chú thay đổi",
agent=reviewer,
context=[research_task, writing_task] # Nhận output từ cả 2 task
)Với Process.sequential, CrewAI tự động truyền output của task trước sang task sau theo thứ tự. Bạn chỉ cần khai báo context khi muốn một Task nhận output từ Task không liền kề, hoặc từ nhiều Task cùng lúc.
Context không giới hạn số lượng Task. Nhưng càng nhiều context, prompt càng dài, token càng tốn. Chỉ truyền context thật sự cần thiết.
Tính năng nâng cao

Task trong CrewAI có nhiều tính năng nâng cao giúp xử lý các tình huống phức tạp.
Chạy bất đồng bộ (async)
Khi bật async_execution=True, Task sẽ chạy song song với Task khác thay vì chờ đợi. Phù hợp khi có nhiều Task độc lập, không phụ thuộc nhau.
# 2 task nghiên cứu chạy song song
task_research_market = Task(
description="Nghiên cứu thị trường AI ở Việt Nam",
expected_output="Báo cáo thị trường 500 từ",
agent=researcher_vn,
async_execution=True # Chạy song song
)
task_research_global = Task(
description="Nghiên cứu thị trường AI toàn cầu",
expected_output="Báo cáo thị trường 500 từ",
agent=researcher_global,
async_execution=True # Chạy song song
)
# Task tổng hợp chờ cả 2 task trên hoàn thành
task_summary = Task(
description="Tổng hợp và so sánh 2 báo cáo thị trường",
expected_output="Bảng so sánh thị trường VN vs thế giới",
agent=analyst,
context=[task_research_market, task_research_global]
)Yêu cầu duyệt từ người dùng (human_input)
Bật human_input=True để Agent tạm dừng và chờ người dùng xác nhận kết quả trước khi chuyển sang bước tiếp theo. Hữu ích cho các quy trình cần kiểm soát chất lượng.
# Task cần người dùng duyệt trước khi tiếp tục
approval_task = Task(
description="Viết email gửi khách hàng quan trọng",
expected_output="Email chuyên nghiệp, đúng format",
agent=writer,
human_input=True # Dừng lại để người dùng xem và duyệt
)Lưu kết quả ra file (output_file)
Thuộc tính output_file tự động lưu output của Task vào file chỉ định. CrewAI sẽ tạo thư mục nếu chưa tồn tại (khi create_directory=True, đây là mặc định).
# Task tự lưu kết quả ra file
report_task = Task(
description="Tạo báo cáo phân tích chi tiết",
expected_output="Báo cáo dạng Markdown",
agent=analyst,
output_file="reports/analysis_2025.md", # Tự lưu vào file
create_directory=True # Tạo thư mục nếu chưa có
)Output có cấu trúc với Pydantic
Khi cần output theo format cố định (JSON, object), dùng output_json hoặc output_pydantic kèm Pydantic model. Agent sẽ trả kết quả đúng schema bạn định nghĩa.
# Ép output theo cấu trúc Pydantic
from pydantic import BaseModel
from typing import List
# Định nghĩa cấu trúc output
class ResearchResult(BaseModel):
topic: str
key_findings: List[str]
sources: List[str]
confidence_score: float
# Task trả về đúng cấu trúc đã định nghĩa
research_task = Task(
description="Nghiên cứu về Large Language Models",
expected_output="Kết quả nghiên cứu có cấu trúc",
agent=researcher,
output_pydantic=ResearchResult # Output sẽ là object ResearchResult
)Sau khi Task hoàn thành, bạn truy cập kết quả qua research_task.output.pydantic để lấy object Python, hoặc research_task.output.json_dict để lấy dictionary.
Guardrail: kiểm tra output tự động
Guardrail là hàm kiểm tra output của Task trước khi chuyển sang bước tiếp theo. Nếu output không đạt, Agent sẽ thử lại.
# Guardrail kiểm tra độ dài output
def check_word_count(output):
"""Kiểm tra bài viết đủ dài"""
word_count = len(output.raw.split())
if word_count < 1000:
return (False, "Bài viết quá ngắn. Cần ít nhất 1000 từ.")
return (True, output)
writing_task = Task(
description="Viết bài blog chi tiết",
expected_output="Bài viết ít nhất 1000 từ",
agent=writer,
guardrail=check_word_count, # Tự kiểm tra trước khi tiếp tục
guardrail_max_retries=3 # Thử lại tối đa 3 lần
)Ví dụ: pipeline research, write, review

Đây là ví dụ hoàn chỉnh kết hợp Agent và Task thành một pipeline xử lý nội dung. Pipeline gồm 3 bước: nghiên cứu, viết bài, và kiểm duyệt.
Bước 1: Khai báo Task trong YAML
# config/tasks.yaml - Pipeline 3 bước
research_task:
description: >
Nghiên cứu chuyên sâu về {topic}. Thu thập thông tin từ
ít nhất 5 nguồn đáng tin cậy. Tập trung vào dữ liệu
mới nhất trong năm 2025.
expected_output: >
Báo cáo nghiên cứu gồm 10-15 điểm chính,
mỗi điểm có trích dẫn nguồn.
agent: researcher
writing_task:
description: >
Dựa trên báo cáo nghiên cứu, viết bài hướng dẫn chi tiết
về {topic}. Bài cần 2000-3000 từ, chia thành 5-7 phần
với heading rõ ràng. Thêm ví dụ code khi phù hợp.
expected_output: >
Bài viết hoàn chỉnh dạng Markdown, có mục lục và kết luận.
agent: writer
output_file: output/{topic}_article.md
review_task:
description: >
Kiểm duyệt bài viết. Kiểm tra độ chính xác thông tin
so với báo cáo nghiên cứu. Sửa lỗi chính tả, ngữ pháp.
Đảm bảo bài viết mạch lạc và dễ hiểu.
expected_output: >
Bài viết đã chỉnh sửa kèm danh sách thay đổi.
agent: reviewerBước 2: Ghép tất cả trong Python
# crew.py - Pipeline hoàn chỉnh với 3 agent và 3 task
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from crewai_tools import SerperDevTool
@CrewBase
class ContentPipeline():
"""Pipeline tạo nội dung: research → write → review"""
agents_config = "config/agents.yaml"
tasks_config = "config/tasks.yaml"
# --- Agents ---
@agent
def researcher(self) -> Agent:
return Agent(
config=self.agents_config['researcher'],
tools=[SerperDevTool()],
verbose=True
)
@agent
def writer(self) -> Agent:
return Agent(
config=self.agents_config['writer'],
llm="gpt-4o-mini",
verbose=True
)
@agent
def reviewer(self) -> Agent:
return Agent(
config=self.agents_config['reviewer'],
llm="gpt-4o",
verbose=True
)
# --- Tasks ---
@task
def research_task(self) -> Task:
return Task(
config=self.tasks_config['research_task']
)
@task
def writing_task(self) -> Task:
return Task(
config=self.tasks_config['writing_task']
)
@task
def review_task(self) -> Task:
return Task(
config=self.tasks_config['review_task']
)
# --- Crew ---
@crew
def crew(self) -> Crew:
return Crew(
agents=[
self.researcher(),
self.writer(),
self.reviewer()
],
tasks=[
self.research_task(),
self.writing_task(),
self.review_task()
],
process=Process.sequential, # Chạy lần lượt
verbose=True
)Bước 3: Chạy pipeline
# main.py - Khởi chạy pipeline
from content_pipeline import ContentPipeline
pipeline = ContentPipeline()
result = pipeline.crew().kickoff(
inputs={'topic': 'CrewAI Framework'}
)
# Xem kết quả từng task
for task_output in result.tasks_output:
print(f"Task: {task_output.description[:50]}...")
print(f"Output: {task_output.raw[:200]}...")
print("---")Khi chạy, pipeline xử lý theo thứ tự: Researcher tìm kiếm thông tin, Writer nhận kết quả nghiên cứu để viết bài, Reviewer đọc cả nghiên cứu lẫn bài viết để kiểm duyệt. Kết quả cuối cùng là bài viết đã qua kiểm duyệt, được lưu tự động vào file.
Nếu bạn chạy pipeline CrewAI thường xuyên, một Pro VPS tại AZDIGI sẽ giúp xử lý ổn định hơn so với chạy trên máy cá nhân, đặc biệt khi cần chạy nhiều Crew cùng lúc.
Câu hỏi thường gặp
Nếu bạn dùng Process.sequential và không gán agent cho Task, CrewAI sẽ báo lỗi. Với Process.hierarchical, Manager Agent sẽ tự phân công Task cho Agent phù hợp nhất dựa trên role. Trong hầu hết trường hợp, nên gán rõ agent cho từng Task.
Với Process.sequential, output của task trước tự động truyền sang task sau. Bạn cần dùng context khi muốn một Task nhận output từ Task không liền kề (ví dụ Task 3 cần output từ Task 1, không chỉ Task 2), hoặc khi dùng Process.hierarchical.
Dùng thuộc tính output_json hoặc output_pydantic kèm Pydantic model. CrewAI sẽ yêu cầu Agent trả kết quả đúng schema bạn định nghĩa. Truy cập kết quả qua task.output.json_dict hoặc task.output.pydantic.
Có. Task với async_execution=True sẽ chạy song song, không chờ task trước hoàn thành. Tuy nhiên, nếu Task khác dùng context trỏ đến Task async, CrewAI sẽ tự động chờ Task async hoàn thành trước khi tiếp tục.
Guardrail chạy trước khi output được chấp nhận, có thể yêu cầu Agent thử lại nếu output không đạt. Callback chạy sau khi Task hoàn thành thành công, dùng để thông báo, log, hoặc trigger hành động tiếp theo. Guardrail kiểm soát chất lượng, callback xử lý hậu kỳ.
Có thể bạn cần xem thêm
- Tool trong CrewAI: mở rộng khả năng agent
- Flow trong CrewAI: xây dựng workflow phức tạp theo sự kiện
- CrewAI là gì? Hướng dẫn xây dựng hệ thống Multi-Agent AI với Python
- Planning và Reasoning trong CrewAI: agent biết lên kế hoạch
- Agent trong CrewAI: tạo AI worker chuyên biệt
- Memory và Knowledge trong CrewAI: agent nhớ và học
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.