Ở các bài trước trong serie CrewAI, mình đã giới thiệu agent, task, và tool. Mỗi thành phần đều có vai trò riêng, nhưng chúng cần một thứ gì đó để gắn kết lại. Thứ đó chính là Crew.
Crew là đơn vị điều phối cao nhất trong CrewAI. Bạn khai báo agents, tasks, chọn quy trình chạy, rồi gọi kickoff(). Crew lo phần còn lại: phân công việc, truyền kết quả giữa các task, và trả về output cuối cùng.
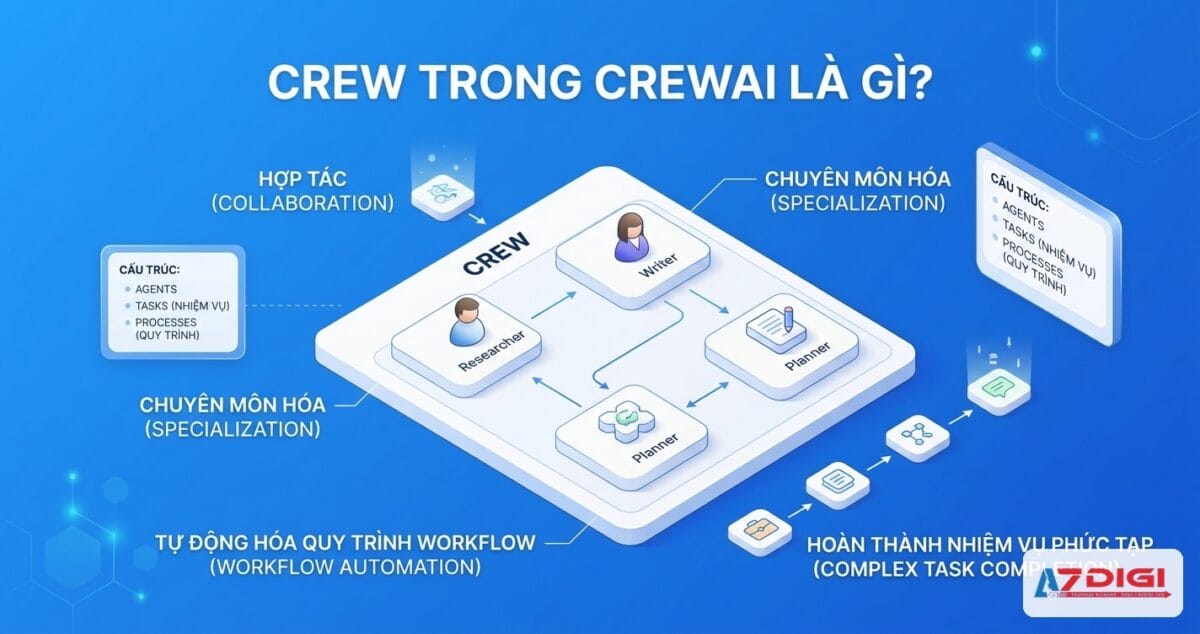
Crew trong CrewAI là gì

Crew đại diện cho một nhóm agent làm việc cùng nhau để hoàn thành một loạt task. Nếu so sánh với đội nhóm thực tế thì Crew giống như một project team: có thành viên (agents), có danh sách việc cần làm (tasks), và có quy trình phối hợp (process).
Các thuộc tính chính của Crew:
- agents: danh sách agent tham gia
- tasks: danh sách task cần thực hiện
- process: quy trình chạy, mặc định là
sequential(tuần tự) - verbose: bật log chi tiết để theo dõi quá trình chạy
- memory: bật bộ nhớ để agent nhớ thông tin giữa các task
- cache: cache kết quả tool (mặc định bật)
- max_rpm: giới hạn số request/phút, tránh bị rate limit từ API
Ngoài ra còn có planning (tự lên kế hoạch trước khi chạy), manager_llm (model cho manager agent trong quy trình phân cấp), và knowledge_sources (nguồn kiến thức chung cho toàn crew).
Tạo Crew cơ bản

Cách đơn giản nhất là khai báo trực tiếp trong code Python:
from crewai import Agent, Task, Crew, Process
# Tạo 2 agent
analyst = Agent(
role="Chuyên viên phân tích",
goal="Phân tích dữ liệu thị trường",
backstory="Bạn có 10 năm kinh nghiệm phân tích tài chính."
)
writer = Agent(
role="Biên tập viên",
goal="Viết báo cáo dễ hiểu từ dữ liệu phân tích",
backstory="Bạn chuyên viết báo cáo cho giám đốc."
)
# Tạo 2 task
analysis_task = Task(
description="Phân tích xu hướng doanh thu Q1 2025.",
expected_output="Báo cáo 3 xu hướng chính kèm số liệu.",
agent=analyst
)
report_task = Task(
description="Viết báo cáo tổng hợp từ kết quả phân tích.",
expected_output="Báo cáo 1 trang, có bullet points và kết luận.",
agent=writer
)
# Ghép thành Crew
crew = Crew(
agents=[analyst, writer],
tasks=[analysis_task, report_task],
process=Process.sequential, # Chạy lần lượt
verbose=True
)
# Khởi chạy
result = crew.kickoff()
print(result)Chỗ quan trọng: thứ tự task trong list tasks quyết định thứ tự thực thi (khi dùng process sequential). Task đầu tiên chạy trước, kết quả của nó tự động trở thành context cho task tiếp theo.
ℹ️ CrewAI cũng hỗ trợ cấu hình bằng YAML (khuyến khích cho dự án lớn). Bạn định nghĩa agents và tasks trong file YAML, rồi dùng decorator @CrewBase, @agent, @task, @crew trong class Python.
Quy trình tuần tự (Sequential)

Sequential là process mặc định. Các task chạy lần lượt theo đúng thứ tự bạn khai báo. Output của task trước trở thành context cho task sau.
crew = Crew(
agents=[researcher, analyst, writer],
tasks=[research_task, analysis_task, write_task],
process=Process.sequential # Task chạy lần lượt
)Luồng chạy:
research_task→ agentresearcherthực hiện, trả kết quảanalysis_task→ agentanalystnhận kết quả bước 1 làm context, thực hiệnwrite_task→ agentwriternhận kết quả bước 2, viết bài cuối
Ưu điểm: dễ hiểu, dễ debug, phù hợp cho pipeline tuyến tính (nghiên cứu → phân tích → viết báo cáo). Nhược điểm: chậm hơn vì phải chờ từng task xong mới chạy task tiếp.
Nếu bạn muốn tuỳ chỉnh context cho task, dùng tham số context trong Task để chỉ định rõ output nào làm input:
# Task 3 dùng output từ task 1 và task 2
write_task = Task(
description="Viết bài tổng hợp.",
expected_output="Bài viết hoàn chỉnh.",
agent=writer,
context=[research_task, analysis_task] # Chỉ định context rõ ràng
)Quy trình phân cấp (Hierarchical)
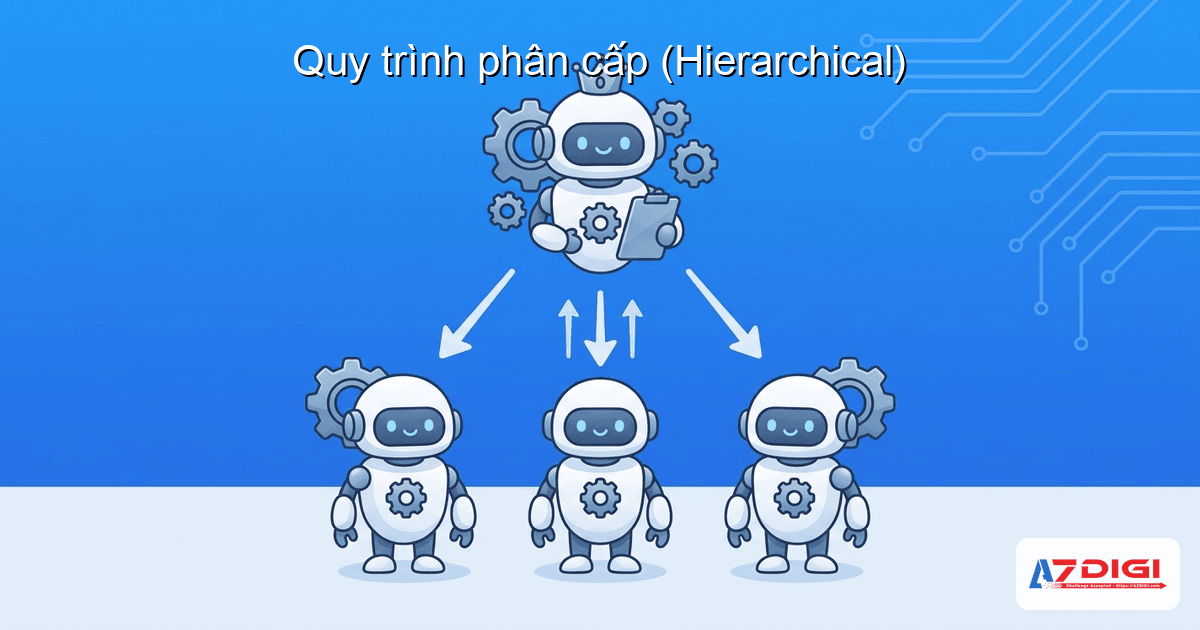
Hierarchical process hoạt động giống mô hình quản lý trong công ty. Có một manager agent đứng trên, phân công task cho các agent bên dưới, kiểm tra kết quả, và quyết định bước tiếp theo.
Để dùng hierarchical, bạn cần chỉ định manager_llm hoặc manager_agent:
from crewai import Crew, Process
# Cách 1: Để CrewAI tự tạo manager, chỉ định model
crew = Crew(
agents=[researcher, analyst, writer],
tasks=[research_task, analysis_task, write_task],
process=Process.hierarchical,
manager_llm="gpt-4o" # Model cho manager agent
)
Hoặc tạo manager agent riêng để kiểm soát hành vi:
from crewai import Agent, Crew, Process
# Tạo manager agent tuỳ chỉnh
manager = Agent(
role="Giám đốc dự án",
goal="Điều phối team hoàn thành báo cáo đúng hạn và chất lượng cao.",
backstory="Bạn có 15 năm kinh nghiệm quản lý dự án công nghệ.",
allow_delegation=True # Cho phép phân công việc
)
# Gán manager agent
crew = Crew(
agents=[researcher, analyst, writer],
tasks=[research_task, analysis_task, write_task],
process=Process.hierarchical,
manager_agent=manager # Manager tuỳ chỉnh
)Điểm khác biệt lớn: trong hierarchical, task không gán cứng cho agent. Manager tự quyết định giao task nào cho agent nào, dựa trên role và capability. Manager cũng kiểm tra output và có thể yêu cầu agent làm lại nếu chưa đạt.
⚠️ Hierarchical process tốn nhiều token hơn sequential vì manager agent cần suy nghĩ, phân tích và ra quyết định. Dùng khi bạn cần sự linh hoạt trong phân công việc.
Kickoff và các cách chạy Crew

CrewAI cung cấp nhiều cách khởi chạy crew tuỳ theo nhu cầu:
1. kickoff() – Chạy đồng bộ cơ bản
# Chạy crew và chờ kết quả
result = crew.kickoff()
print(result.raw) # Kết quả dạng text
print(result.token_usage) # Số token đã dùngBạn cũng truyền input động cho crew qua inputs:
# Truyền biến vào crew
result = crew.kickoff(inputs={
"topic": "xu hướng AI 2025",
"language": "Vietnamese"
})2. kickoff_async() – Chạy bất đồng bộ
import asyncio
# Chạy async, không block main thread
async def run():
result = await crew.kickoff_async(inputs={"topic": "AI agents"})
return result
result = asyncio.run(run())
3. kickoff_for_each() – Chạy lặp với nhiều bộ input
# Chạy crew với nhiều bộ input khác nhau
inputs_list = [
{"topic": "Machine Learning"},
{"topic": "Computer Vision"},
{"topic": "NLP"}
]
# Crew sẽ chạy 3 lần, mỗi lần với 1 bộ input
results = crew.kickoff_for_each(inputs=inputs_list)Kết quả trả về từ kickoff() là object CrewOutput, có các thuộc tính:
- raw: kết quả dạng text thuần
- json_dict: kết quả dạng dict (nếu output được format JSON)
- pydantic: kết quả dạng Pydantic model (nếu đã cấu hình output schema)
- tasks_output: danh sách output từ từng task riêng lẻ
- token_usage: thống kê số token đã sử dụng
Ví dụ hoàn chỉnh: crew 3 agents sequential

Đây là ví dụ đầy đủ: crew gồm 3 agent chạy tuần tự, nghiên cứu → phân tích → viết báo cáo về một chủ đề do người dùng chọn.
import os
from crewai import Agent, Task, Crew, Process
from crewai_tools import SerperDevTool
# Cấu hình
os.environ["OPENAI_API_KEY"] = "your-openai-key"
os.environ["SERPER_API_KEY"] = "your-serper-key"
# === Tool ===
search_tool = SerperDevTool()
# === Agent 1: Nghiên cứu ===
researcher = Agent(
role="Chuyên viên nghiên cứu",
goal="Thu thập thông tin mới nhất về {topic}",
backstory=(
"Bạn rất giỏi tìm kiếm thông tin từ nhiều nguồn. "
"Bạn luôn kiểm tra chéo dữ liệu để đảm bảo chính xác."
),
tools=[search_tool],
verbose=True
)
# === Agent 2: Phân tích ===
analyst = Agent(
role="Chuyên viên phân tích",
goal="Phân tích dữ liệu và rút ra insight quan trọng về {topic}",
backstory=(
"Bạn có tư duy phản biện tốt, "
"luôn nhìn vấn đề từ nhiều góc độ."
),
verbose=True
)
# === Agent 3: Viết báo cáo ===
writer = Agent(
role="Biên tập viên",
goal="Viết báo cáo tổng hợp, dễ hiểu, có cấu trúc rõ ràng",
backstory=(
"Bạn chuyên viết nội dung cho đối tượng không chuyên. "
"Bạn biết cách trình bày phức tạp thành đơn giản."
),
verbose=True
)
# === Task 1: Thu thập dữ liệu ===
research_task = Task(
description=(
"Tìm kiếm thông tin mới nhất về {topic}. "
"Tập trung vào: xu hướng, số liệu, ví dụ thực tế. "
"Ghi nguồn cho mỗi thông tin."
),
expected_output=(
"Tài liệu nghiên cứu gồm 5-7 điểm chính, "
"mỗi điểm có nguồn tham khảo."
),
agent=researcher
)
# === Task 2: Phân tích ===
analysis_task = Task(
description=(
"Phân tích tài liệu nghiên cứu. "
"Xác định 3 insight quan trọng nhất. "
"Đánh giá cơ hội và rủi ro."
),
expected_output=(
"Bản phân tích gồm: 3 insight chính, "
"bảng cơ hội/rủi ro, và khuyến nghị."
),
agent=analyst
)
# === Task 3: Viết báo cáo ===
report_task = Task(
description=(
"Viết báo cáo tổng hợp từ kết quả phân tích. "
"Cấu trúc: tóm tắt, 3 phần chính, kết luận. "
"Viết cho người đọc không chuyên về kỹ thuật."
),
expected_output=(
"Báo cáo hoàn chỉnh dạng markdown, "
"khoảng 800-1000 từ, có heading rõ ràng."
),
agent=writer,
output_file="reports/output.md"
)
# === Tạo Crew ===
crew = Crew(
agents=[researcher, analyst, writer],
tasks=[research_task, analysis_task, report_task],
process=Process.sequential,
verbose=True,
planning=True # Crew sẽ lên kế hoạch trước khi chạy
)
# === Chạy ===
result = crew.kickoff(inputs={"topic": "AI Agents trong doanh nghiệp"})
# In kết quả
print("=== BÁO CÁO ===")
print(result.raw)
print(f"\nToken đã dùng: {result.token_usage}")Mấy điểm đáng chú ý:
- Biến
{topic}trong goal và description sẽ được thay thế bằng giá trị từinputs planning=Truegiúp crew tự lên kế hoạch thực thi trước khi bắt đầu. Kế hoạch này được thêm vào mô tả từng taskoutput_fileở task cuối lưu kết quả ra file, tiện cho việc xử lý sau- Bật
verbose=Trueđể xem log chi tiết: agent nào đang chạy, gọi tool nào, kết quả trung gian ra sao
💡 Muốn tự host hệ thống multi-agent trên server riêng? Tham khảo Pro VPS tại AZDIGI để có tài nguyên CPU/RAM phù hợp chạy LLM và agent framework.
Câu hỏi thường gặp
Crew trong CrewAI khác gì Agent?
Agent là cá nhân thực hiện công việc. Crew là đơn vị quản lý gom nhiều agent và task lại, quyết định quy trình chạy. Một crew có nhiều agent, mỗi agent xử lý một hoặc nhiều task.
Nên dùng Sequential hay Hierarchical?
Sequential phù hợp khi workflow rõ ràng, tuyến tính (A xong rồi B rồi C). Hierarchical phù hợp khi cần linh hoạt phân công, manager tự quyết định giao việc cho ai. Sequential tiết kiệm token hơn.
Có thể chạy nhiều crew cùng lúc không?
Có. Bạn tạo nhiều crew riêng biệt và dùng kickoff_async() để chạy song song. Hoặc dùng CrewAI Flow để điều phối nhiều crew trong một pipeline phức tạp hơn.
kickoff_for_each dùng khi nào?
Khi bạn muốn chạy cùng một crew với nhiều bộ dữ liệu khác nhau. Ví dụ: phân tích 10 đối thủ cạnh tranh, mỗi đối thủ là một bộ input riêng. Crew sẽ chạy lặp lại cho từng bộ.
Crew có bộ nhớ không?
Có. Bật memory=True khi tạo crew để agent nhớ thông tin giữa các task. CrewAI hỗ trợ short-term memory, long-term memory, và entity memory. Bộ nhớ dùng embeddings, cần cấu hình embedder (mặc định là OpenAI).
Serie CrewAI vẫn còn tiếp. Bài sau mình sẽ đi vào Flow, cách điều phối nhiều crew trong pipeline phức tạp, kết hợp logic if/else và xử lý song song.
Có thể bạn cần xem thêm
- Hermes Agent là gì? Hướng dẫn cài đặt và sử dụng
- Dùng AI để gỡ lỗi, deploy và vibe code website trên hosting cPanel
- vLLM là gì? Khi nào nên dùng vLLM thay Ollama
- MCP là gì? Cách AI Agent kết nối tool và dữ liệu bên ngoài
- Flowise là gì? Khi nào nên self-hosted trên VPS để tạo chatbot AI
- vLLM là gì? Khi nào nên dùng vLLM thay Ollama
Về tác giả

Trần Thắng
Chuyên gia tại AZDIGI với nhiều năm kinh nghiệm trong lĩnh vực web hosting và quản trị hệ thống.